
Googleをマスターするための60以上のGoogle検索のヒント、コツ、演算子、およびコマンド
公開: 2021-04-25
グーグルを使うのは簡単です、あなたは同意すると確信しています!
検索バーにクエリを入力するだけで、関連する一連の結果が整理され、順番にランク付けされます。
Googleの検索は簡単な作業ですが、ニッチなトピックに関するゲストの投稿を受け入れるWebサイトなど、もう少し具体的なものを探している場合は、通常のキーワード検索ではうまくいかないことがわかります。
Googleを最大限に活用したい場合は、基本的なクエリに頼ることはできません。 高度な検索演算子の力を活用する必要があります。
あなたがベテランの検索専門家であるか、最も基本的なグーグルスキルしか持っていないかどうか…
この特別なグーグル検索ガイドは、あなたがこれらの「チートコード」を活用してグーグル検索マスターになることができるように、そこにいるすべてのグーグル検索オペレーターを案内します。
より洗練された検索結果が得られるだけでなく、特定のニッチまたは目的をターゲットにするために検索クエリに焦点を合わせることができます。
このガイドでは、Google検索演算子の完全なリストと、同僚を驚かせるために使用できるいくつかの楽しいGoogleのトリックとイースターエッグについて説明します。
また、Google検索タスクをより生産的かつ効率的にするために役立つ15の実用的なヒントと戦術をまとめました。
- SEOのための基本的なGoogle検索演算子
- SEOのための高度なGoogle検索演算子
- みんなのためのグーグル検索のヒント(グーグルベターへの道)!
- 避けるべき信頼性の低い検索コマンド
- 隠されたグーグル検索はあなたを(おそらく)知らなかったトリック
- Google検索演算子を習得するための15の実用的なヒント
それに飛び込みましょう。
無料ボーナス:検索コマンドジェネレーターにアクセスすると、数十の検索演算子が即座に生成され、Googleにコピーして貼り付けて、まとめ、リソースページ、ゲスト投稿の機会などを見つけることができます。
Google検索演算子とは何ですか?
検索演算子は、より洗練された詳細な検索結果を返すために検索クエリに含めることができる特殊文字とパラメーターです。

検索演算子は、結果を正確なフレーズに絞り込んだり、結果から特定の用語を除外したりできるようにすることから、すべての機能をカバーします。 検索演算子を組み合わせて使用すると、一般的なクエリに隠されている詳細情報を見つけることができます。
たとえば、食品ブログを運営していて、最近、古ダイエットを成功させるためのガイドを書いたとします。
そのすべての作業の後、あなたは自分の投稿を古関連のリソースに含めたいと思っています。
パレオダイエットリソースを検索すると、ハウツーガイドからリソースページまで、さまざまな結果が返されます。
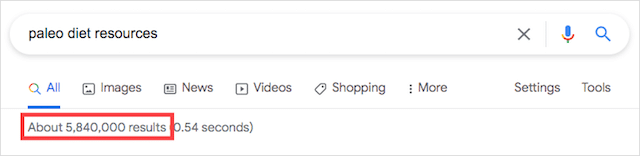
584万の結果は、あなたがくしでとかすには多すぎます。
ここで検索演算子が役立ちます。
適切な検索コマンドを使用することで、580万件の結果をわずか6,990件に変えることができます。
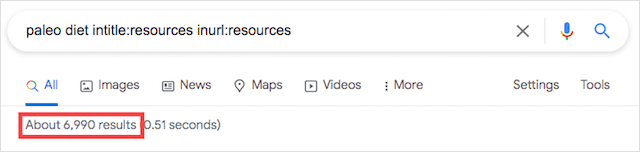
はるかに管理しやすい数!
さらに、検索結果のすべてのリンクは純粋にリソースページであり、その非常に重要なバックリンクのためにアクセスしたいサイトを選択することができます。
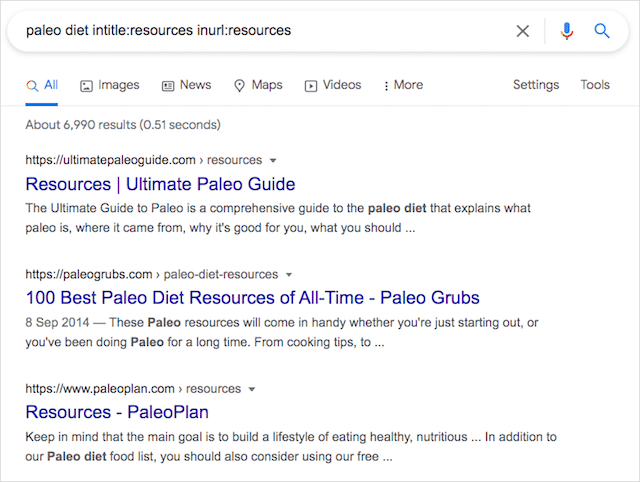
言い換えると:
検索演算子の適切な組み合わせを使用することにより、これらの複雑な結果を、ターゲットを絞った関連性の高い結果に絞り込むことができます。
ただし、これらの検索演算子を毎日のGoogle検索タスクに適用する方法に取り組む前に、各コマンドをより詳細に分類してみましょう。
基本的なGoogle検索演算子とコマンドリスト
これらの基本的な検索演算子は、標準のテキスト検索をより実用的でフィルター処理された検索結果に変換するのに役立つ便利なコマンドです。
これらの属性を検索用語に適用すると、検索の可能性のまったく新しい世界が開かれます。
"検索語"
引用符( "")を使用すると、完全一致検索が強制され、検索結果が絞り込まれます。 1つの単語を囲む場合、引用符は同義語を除外します。

例: 「ヨガ」
また
2つの異なる検索用語の間で結果を返すようにGoogleに指示する検索ディレクティブ。 これは、2つのキーワードに関連する検索結果を見つけるのに役立ちます。 ORの代わりにパイプ記号(|)を使用することもできます。

例:ヨガまたはピラティス/ヨガ| ピラティス
と
AND演算子は、検索バーに入力された検索用語に関連する結果を返します。 Googleのアルゴリズムは、複数の検索用語とフレーズ検索の違いを正確に判断できるため、AND演算子はそれほど違いはありません。

例:ひまわりと庭
-除外する
検索語の前にハイフン(またはマイナス)を追加すると、コンテンツ内にそのキーワードを含むページが除外されます。 複数の検索語を検索結果に表示しないようにするには、追加のハイフンが必要です。

例:ソーシャルメディア-facebook -instagram
サイト:
「サイト:」は、検索結果を特定のドメインに制限できる検索演算子です。 「site:」コマンドは、「intitle:」などの他の演算子と組み合わせて使用すると、検索用語に言及している特定のページを検索したり、マイナス(-)演算子を使用して特定のドメインを除外したりする場合に最も効果的です。

例: site:seosherpa.com
*
アスタリスク記号は、検索ではワイルドカード文字と見なされます。これは、Googleがアスタリスクを「空白を埋める」またはプレースホルダーコマンドとして扱うためです。 アスタリスクが使用されている場合、Googleは検索語またはフレーズに最適なものを見つけようとします。

例:オバマ*寄付
()
角かっこは、複数の検索用語または演算子をグループ化することにより、検索結果を制御するのに役立ちます。 キーワードをかっこで囲むと、検索をより戦略的にし、検索結果を絞り込むことができます。

例:(バスケットボールとサッカー)アスリート
#..#
両側に2つの数字が付いた(..)を使用すると、検索結果が含まれる数字の範囲に絞り込まれます。 (..)演算子は、結果に一貫性がない場合もありますが、日付範囲または価格内の特定の情報を見つけるのに役立ちます。

例: wwdc基調講演2010..2014/白いシャツ$25 .. $ 50
@
ソーシャルメディアハンドルから投稿された結果のみを表示するように検索を制限する場合は、キーワードの前に「@」記号を使用します。 「@」記号は、ブランドのソーシャルメディアハンドルや特定のソーシャルメディアプラットフォームを使用するビジネスを見つけるために使用できます。

例: @apple / facebook @apple
高度なGoogle検索演算子とコマンド:完全なリスト
これで、検索演算子の基本的な構成要素に精通しました。
次に、正確な検索結果を返すのに役立つ、より高度な検索演算子について詳しく見ていきましょう。
intitle:
「intitle:」コマンドは、ページタイトルで使用されている単語またはフレーズを含むページの結果を返します。
完全に一致するフレーズを含むページのみを検索するには、検索語を引用符( "")で囲みます。

例: intitle:apple / intitle:” apple iphone 12”
allintitle:
「intitle」に似ています。
ただし、「allintitle:」演算子を使用すると、検索語に含まれるすべての単語を含むページタイトルの結果を返すことができます。

この検索オペレーターは、SEOコンテンツとリンク構築の調査に便利であり、アウトリーチの適切なターゲットとなる可能性のある関連コンテンツをすばやく特定するのに役立ちます。
例: allintitle:imageseoガイド
inurl:
URLに特定の単語(または複数の単語)が含まれているページを検索する場合は、「inurl:」を使用します。

例: inurl:airpods
allinurl:
「allinurl:」コマンドは、ページのURLで検索されたすべてのキーワードを含む結果を返す特定の検索演算子です。 長すぎる検索フレーズを使用すると、検索ボリュームが大幅に減少したり、結果がまったく返されなかったりする可能性があります。

例: allinurl:seoコンテンツの書き込み
intext:
「intext」:Google検索演算子は、ページの本文内の個々の単語やフレーズを見つけるのに役立ちます。 この検索演算子は実質的に他のGoogle検索と同じように機能するため、「Intext:」が使用されることはめったにありません。

このコマンドは、「site:」などの別の検索演算子を使用して特定のページコンテンツを検索する場合に最も効果的です。
例: intext:samsungスマートフォン
allintext:
「Allintext:」を使用すると、ページの本文またはドキュメントテキストで、検索語に含まれる指定されたすべてのキーワードを検索できます。

検索語に引用符( "")を組み合わせると、検索がさらに絞り込まれ、完全一致の結果が表示されます。
例: allintext:samsung galaxy 10 / allintext:” samsung galaxy 10”
ファイルの種類:
「filetype:」を使用すると、検索結果がPDF、DOCX、PPTなどの指定されたファイルタイプに制限されます。「filetype:」演算子を単独で使用することはできません。 代わりに、結果を表示するために別の用語と組み合わせる必要があります。
「ファイルタイプ:」は、画像タイプ(PNG、JPG、GIFなど)を指定するためにも使用できます。

「ext:」コマンドは、検索語の「filetype:」を置き換えて、同じ結果を返すことができます。
例:コンテンツマーケティングfiletype:pdf
関連している:
市場や競合他社の調査を行う場合、「関連:」が役立ちます。 「related:」演算子は、検索バーに含めたターゲットURLに類似したドメインを見つけるのに役立ちます。

この検索コマンドは、より大きなドメインで最適に機能します。
例: related:semrush.com
AROUND(X)
近接検索演算子「AROUND(X)」を使用すると、互いにX語の単語を含む任意の検索用語を含むページを検索できます。 「デジタルマーケティングAROUND(3)SEO」のような検索用語は、「デジタルマーケティング」と「SEO」が3語以内で区切られた結果を返します。

例: AROUND(3)SEOのデジタルマーケティング
キャッシュ:
サイトまたはドメインがGoogleのボットによって最後にクロールされたのはいつかを知りたい場合は、「cache:」コマンドを使用してください。 「cache:」演算子は、特定のドメインまたはURLの最新のキャッシュを返します。 これは、Googleがインデックスに登録したサイトでのみ機能します。

注:ドメインのキャッシュバージョンは外観が異なり、キャッシュバージョンの日付を指定するバナーが表示されます。
例: cache:clickjam.com
ソース:
「source:」演算子を使用すると、Googleニュースで指定したソースのニュースコンテンツを表示できます。 「source:」コマンドを使用すると、検索にリストされたソースからのキーワード関連のすべてのWebページが表示されます。

例:アップルソース:フォーブス
blogurl:
特定のドメインのブログを検索する場合は、「blogurl:」演算子を使用します。 「blogurl:」コマンドは、2011年に廃止されたGoogleブログ検索で最初に使用されました。このコマンドは現在廃止されていますが、一貫性はありませんが、関連する結果が返されることがあります。

例: blogurl:microsoft.com
loc:placename
検索を特定の場所に絞り込むには、「loc:」コマンドを使用します。 場所固有の検索は、1つの地理的領域の特定のブランドまたはビジネスをターゲットにする場合に最も効果的です。

完全に非推奨ではありませんが、結果は信頼できない傾向があります。
例:マーケティングエージェンシーloc:new york
位置:
「loc:」と似ていますが、「location:」演算子は、その特定の地域のGoogleニュースからニュース結果を返します。

上記と同様に、「location:」は正式に廃止されていませんが、検索結果に一貫性がない可能性があります。
例:マーケティング代理店の場所:ニューヨーク
Google検索のヒントとコツ(Googleをより良くする方法)!
非SEOタスクのためにGoogle検索をより効果的に使用したいですか?
日常のグーグルで検索効率を最大化するためのGoogle検索のヒントとコツは次のとおりです。
$/€
価格で商品を検索する必要がある場合は、米国とユーロの記号が便利です。 現在、価格を表示する通貨記号は$と€のみです。 GBP(£)、JPY(¥)のような他の一般的な通貨は一貫性のない結果を提供します。

検索をさらに絞り込むために、ピリオドと通貨記号を組み合わせて、「イヤホン$19.99」のような正確な価格を表示できます。
例: iphone 12 $ 1000
の中へ
2つの同等のユニット間で変換する場合は、「in」または「to」検索コマンドを使用します。 「in」および「to」演算子は、通貨、温度、速度などの多数の変換アプリケーションに使用できます。

「in」コマンドを使用すると、ナレッジカードの検索結果が表示されます。
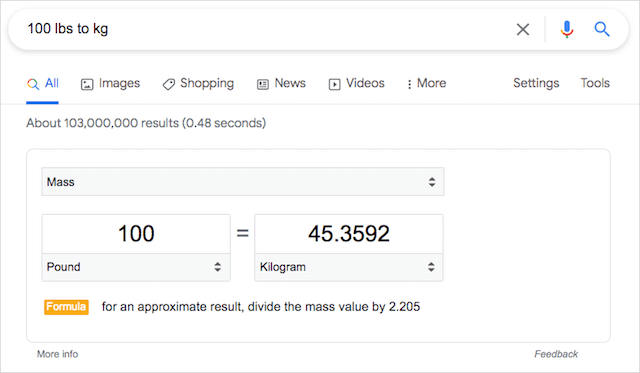
例: 100 lbs to kg / 100 usd to eur
定義:
「define:」演算子を使用すると、OxfordLanguagesが提供するGoogleの組み込み辞書にアクセスできます。

ナレッジカードスタイルの辞書の結果には、検索語の単語と類義語を音声で発音できるオーディオプレーヤーも含まれています。
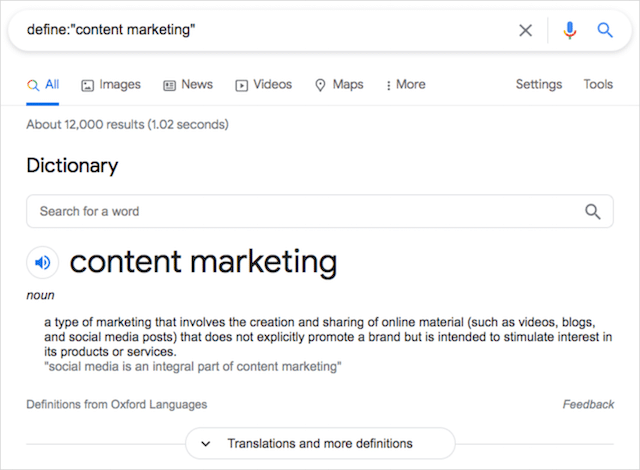
コンテンツマーケティングのように複数のキーワードで辞書にアクセスするには、引用符を使用する必要があります。 それ以外の場合、検索は単に従来のGoogle検索結果を返します。
例: define:entrepreneur / define:”コンテンツマーケティング”
天気:
「weather:」演算子を使用すると、特定の場所の天気と気温を確認できます。

検索結果は、天気予報のスニペットになります。 天気特集スニペットの下には、他の人気のある信頼性の高い天気ウェブサイトがあります。

例: weather:dubai
地図:
検索結果の[マップ]タブをクリックせずに、GoogleのSERPから直接マップ結果を表示するには、「map:」コマンドを使用します。

「map:」演算子は、最上位の結果として位置検索を提供します。
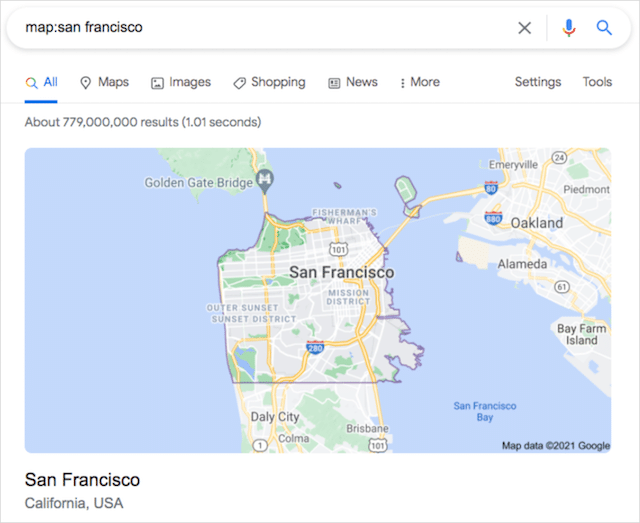
例: map:san francisco
映画:
特定の映画についてもっと知りたいですか?
「movie:」コマンドは、予告編、映画の概要、レビューなど、特定の映画に関する結果を返します。 映画がまだ映画館で上映されている場合、結果には映画の上映時間も表示されます。

例:映画:ソーシャルネットワーク
在庫:
特定のティッカーの株式情報を表示するには、「stocks:」コマンドを使用します。

検索では、オーガニックリストの上にナレッジカードスタイルの結果が返されます。 「株式:」は、会社名または株式のティッカーシンボルのいずれかで機能します。
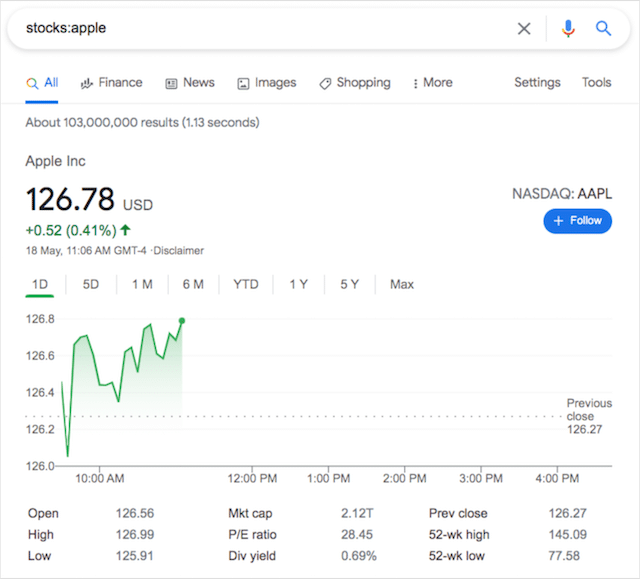
例: stocks:apple / stocks:aapl
近く
Googleマップの検索オペレーターである「near」コマンドは、IPアドレスまたは場所の近くに地理的に位置する検索用語に一致する特定のビジネスを一覧表示します。

基本的なGoogle検索に「near」を使用した場合でも、最初の結果はGoogleマップウィジェットとローカル3パックになる傾向があります。
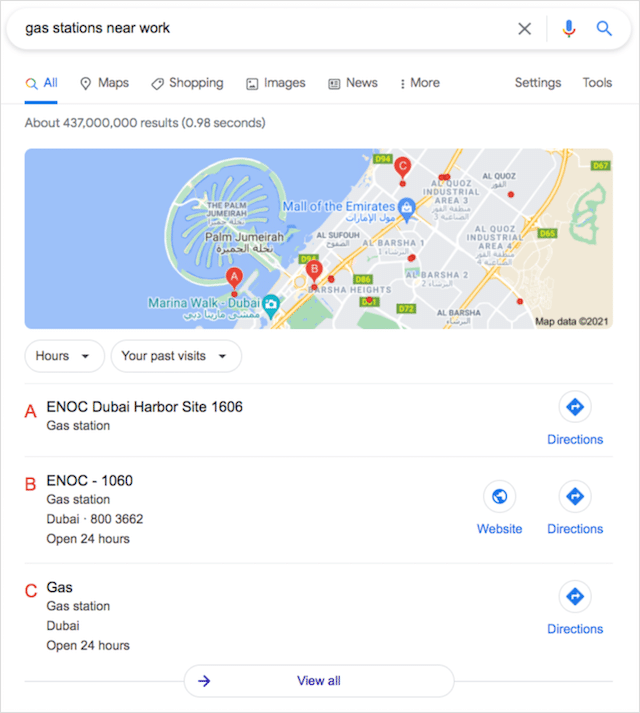
例:職場近くのガソリンスタンド
"事業の種類"
別のGoogleマップ検索オペレーターである「業種」コマンドは、特に指定がない限り、特定の地域、通常はお住まいの地域の近くにある既知のお店の選択を返します。

Googleマイビジネスのリスティングでは、ビジネスカテゴリを慎重に検討して、関連する結果が表示されるようにすることが重要です。
例:カフェまたはレストラン
信頼性の低い、または廃止された検索演算子とコマンド
基本的な検索コマンドと高度な検索コマンドについて説明したので、廃止された、または現在は機能していないGoogle検索演算子を見てみましょう。
言い換えると、これらは現在機能しないため、または将来機能しないため、使用を停止する必要がある検索演算子です。
〜
チルダ(〜)記号は、以前は類似のキーワードまたはフレーズを検索するために使用されていました。 「〜」を使用すると、Google検索は検索クエリに関連する同義語を配信します。 Googleはデフォルトで同義語を返すことができるようになり、この検索演算子は廃止されました。
例:イースター〜装飾
+
チルダ記号のようなプレフィックスに「+」演算子を使用すると、Googleは指定されたクエリに対して完全一致の検索結果を返すように強制されます。 Googleは、ソーシャルネットワークGoogle+を立ち上げたときに、この検索オペレーターを非推奨にしました。
「+」コマンドは、Google検索で引用符(」「)機能に置き換えられました。
例: gates + microsoft
daterange:xxxxx-xxxxx
特定の日付を検索するには、「daterange:」演算子を使用する必要がありました。
唯一の注意点は、この検索コマンドではジュリアン日付(yyddd日付形式)を使用する必要があるということでした。 また、グレゴリオ暦(mm / dd / yyyy)を使用しているため、この演算子の使用には注意が必要です。
さらに、Google検索は「daterange:」機能で一貫性のない結果を返します。
例: wwdc daterange:11278-13278
inposttitle:
「inposttitle:」演算子はGoogleブログ検索と組み合わせて使用され、検索ユーザーがブログタイトルに指定された検索用語を含むブログ投稿を検索できるようにしました。 Googleがブログ検索を中止すると、この検索コマンドは機能しなくなります。
例: inposttitle:減量の練習
allinpostauthor:
「allinpostauthor:」を使用すると、検索ユーザーはGoogleブログの検索カテゴリで特定の著者を見つけることができます。 このコマンドは、特定の個人によって書かれたコンテンツをすばやく簡単に見つける方法でした。
この検索演算子は、2011年にGoogleブログ検索が中止されたときに機能しなくなりました。
例: allinpostauthor:rand fishkin
inpostauthor:
別のGoogleブログ検索演算子である「postauthor:」コマンドを使用すると、特定の作成者が作成したブログコンテンツを検索できます。 「allinpostauthor:」とは異なり、検索を特定の著者に絞り込むには、引用符( "")を使用する必要がありました。
例: inpostauthor:” james reynolds”
情報:
「info:」演算子は、以前、検索スニペットやGoogleキャッシュリンクから、検索クエリに関連する同様のサイトまで、サイトに関する詳細情報を提供していました。 Googleは2017年にその検索コマンドを廃止し、「info:」には検索スニペットのみが表示されるようになりました。
「id:」コマンドは「info:」演算子と同じであり、同じ結果を返します。
例: info:seosherpa.com
リンク:
ターゲットドメインにリンクされているページを検索する場合は、「link:」コマンドを使用します。 Googleは2017年にこの検索演算子を正式に廃止しましたが、有益であることが証明された結果が返される場合があります。
そうは言っても、そこには多くの被リンク分析ツールがあるので、私はお勧めします
例: link:nytimes.com
電話帳:
Google検索で番号を検索したい場合は、かつて「phonebook:」コマンドを使用できました。 多くの企業や個人がこの機能が「無限の面倒な原因」を引き起こしたと主張した後、Googleは2010年にこの検索オペレーターを削除することを決定しました。
例:電話帳:ビル・ゲイツ
#
検索エンジンのソーシャルネットワークGoogle+の一部としてGoogle検索に導入されたハッシュタグ/ポンド記号「#」演算子により、検索ユーザーはFacebookやTwitterなどのソーシャルメディアネットワークからハッシュタグを返すことができました。
Google+が機能しなくなったときにGoogleによって非推奨にされましたが、hashtagコマンドは一貫性がないものの、結果を返します。
例: #contentmarketing
あなたが試してみたい隠されたGoogleSeachのトリック
Google検索のパフォーマンスを最大化し、Googleに優れた結果を提供させる方法がわかったので、友人や同僚を驚かせたり、グーグルでより多くのことを達成したりするために使用できる楽しいGoogleのトリックをいくつか紹介します。
タイマー
気の利いたGoogle検索機能である「タイマー」機能を使用すると、タイマーを秒単位で設定できます。 Googleの組み込みタイマーにアクセスするには、検索バーに「タイマー」と入力するか、Googleがカウントダウンする時間を入力します。
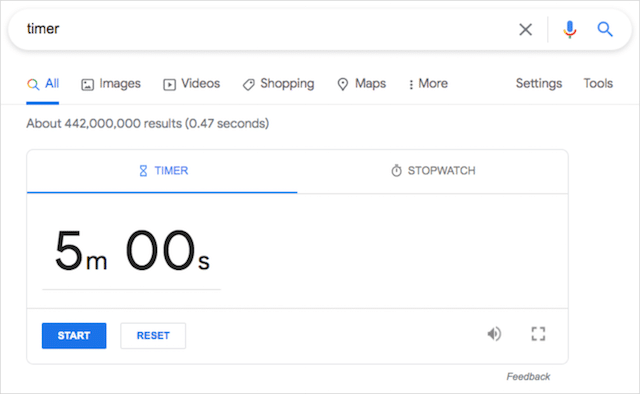
後者はすぐにカウントダウンを開始しますが、前者はカスタム時間を追加できます。
このGoogleトリックをトリガーする方法: 15分タイマー/タイマー
バレルロール/zまたはrを2回行う
Googleの検索ページが360度宙返りを実行するのを見たいですか? 検索バーに「バレルロールを行う」または「zまたはrを2回」と入力し、Enterキーを押すだけです。 「バレルロールを行う」イースターエッグは2011年11月に最初に導入され、それ以来、Googleの多くの隠されたトリックの定番となっています。
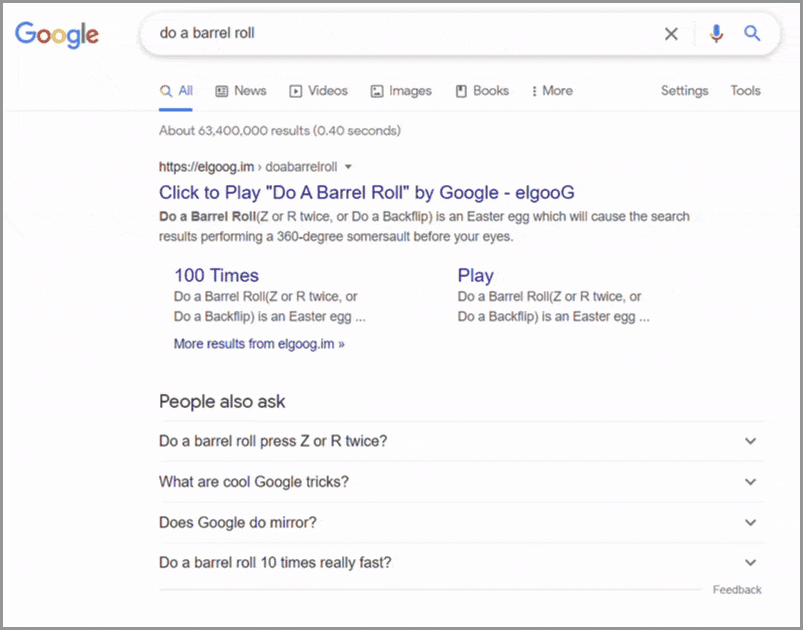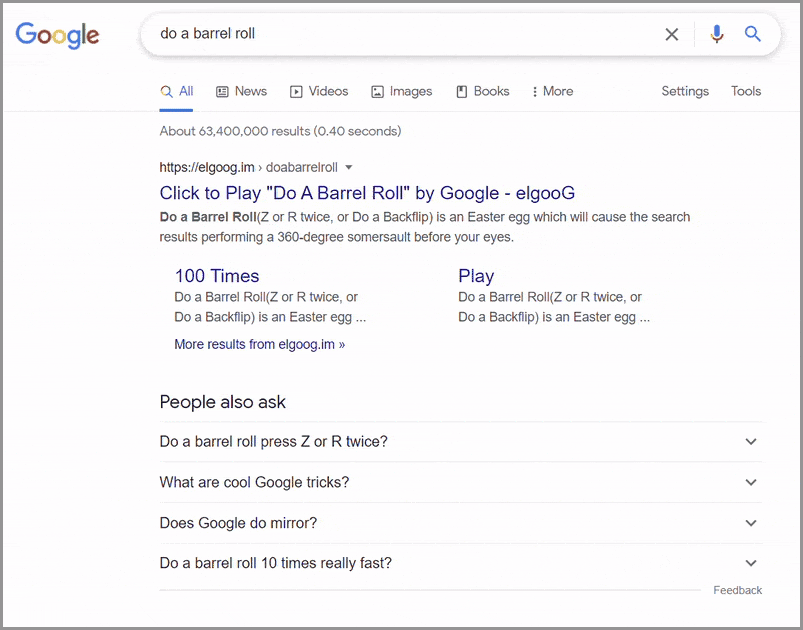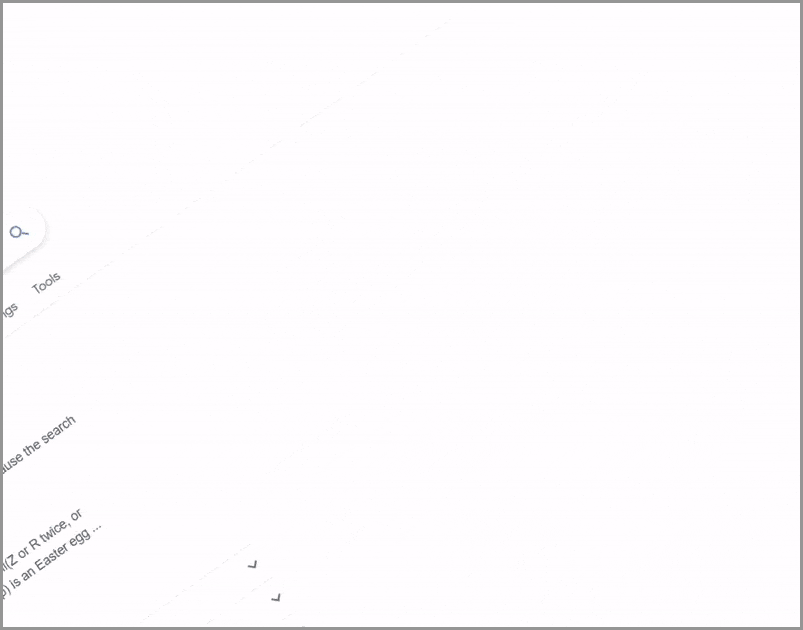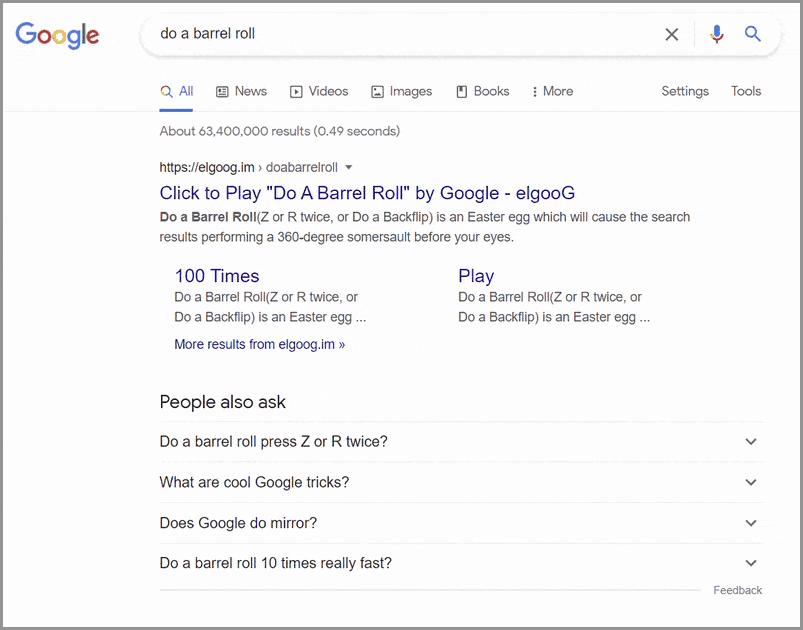
「バレルロールを行う」という用語は、1997年のビデオゲームであるスターフォックス64によって、ペッピーヘアという名前のノンプレイ(NPC)キャラクターによって広められました。 「zまたはrを2回」コマンドは、プレーヤーがNintendo64コントローラーで操作を実行する方法でした。
このGoogleトリックをトリガーする方法:バレルロール/zまたはrを2回実行します
斜め
Google検索が少し右に傾いてどのように見えるかを見たいと思ったことはありますか? さて、グーグルのソフトウェアエンジニアはあなたの要求を聞いて、あなたのためにイースターエッグだけを含めました。 Googleの検索バーに「askew」と入力すると、わずかに歪んだ結果が返されます。
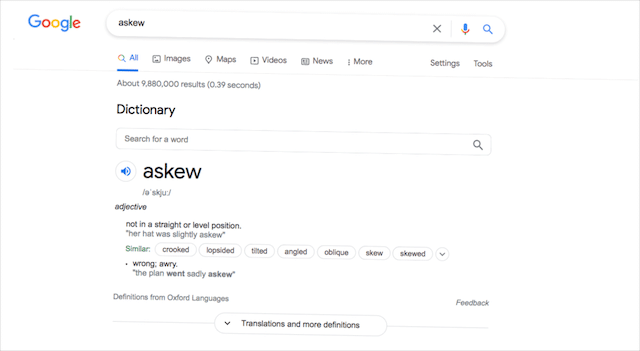
「slanted」や「tilt」などの同様の検索は過去に機能していましたが、「askew」は、Google検索が偏ったままになる唯一の検索用語のようです。
このGoogleのトリックをトリガーする方法:斜め
フェスティバス
となりのサインフェルドのファンなら、12月23日に祝われるクリスマスの代替品である「フェスティバス」について聞いたことがあるでしょう。この反消費主義の休日を祝い始めたい場合は、CNNに役立つ記事があります。フェスティバス気分で。
となりのサインフェルドのファンの間で休日がカルトクラシックになっていることから、Googleの誰かがフェスティバスの休日を祝う必要があることは明らかです。 このフェスティバスの奇跡を自分で体験するには、Google検索に「festivus」と入力すると、フェスティバスのポールで飾られたGoogleの検索ページが表示されます。
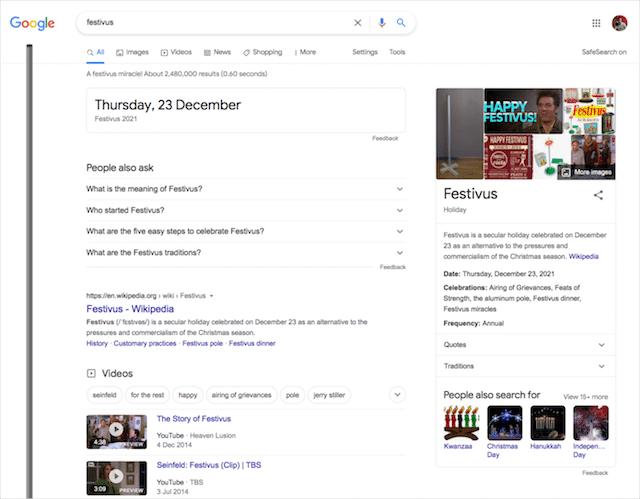
このGoogleのトリックをトリガーする方法: festivus
アナグラム
定義上、アナグラムは、別の単語またはフレーズの文字を再配置することによって形成される単語またはフレーズです。 アナグラムの例としては、アイスマンの映画、リッスンのサイレント、ダーティルームの寮などがあります。
Google検索に「アナグラム」と入力すると、検索エンジンが意図的に再生し、独自のアナグラムを配信します。これを以下に示します。
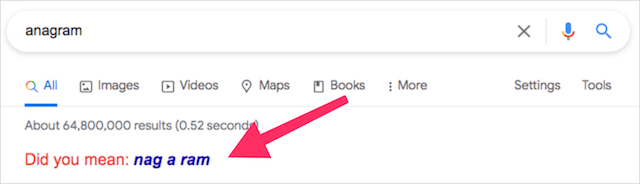
「アナグラムの定義」と入力すると、別の遊び心のあるアナグラムが表示されます。
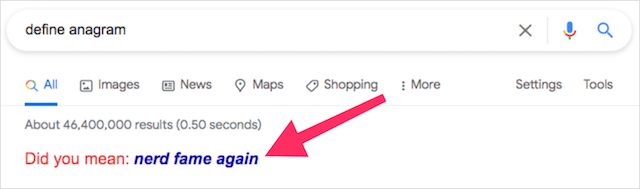
このGoogleのトリックをトリガーする方法:アナグラム/アナグラムの定義
Zergラッシュ
ビデオゲームStarCraftで人気のある「zergrush」は、圧倒的な数の弱い敵がプレイヤーを攻撃するリアルタイム戦略のビデオゲーム戦術です。 Googleは、「zerg rush」イースターエッグを導入することで、リアルタイム戦略ゲームの仲間入りをすることにしました。
元々、隠されたゲームにアクセスするには、Googleの検索バーに「zergrush」と入力するだけでした。 検索ユーザーは、勝つためにSERPに登場したGoogleOの軍隊を破壊しなければなりませんでした。 Osは、それらを繰り返しクリックすることで打ち負かされる可能性があります。
Googleは2012年に「zergrush」イースターエッグを追加しましたが、その後削除しました。
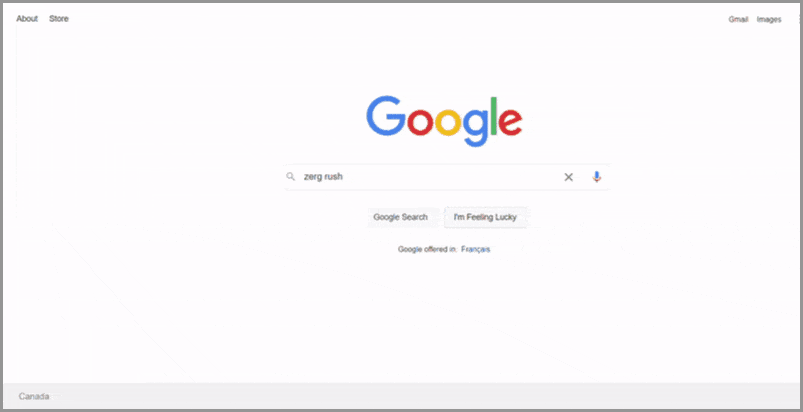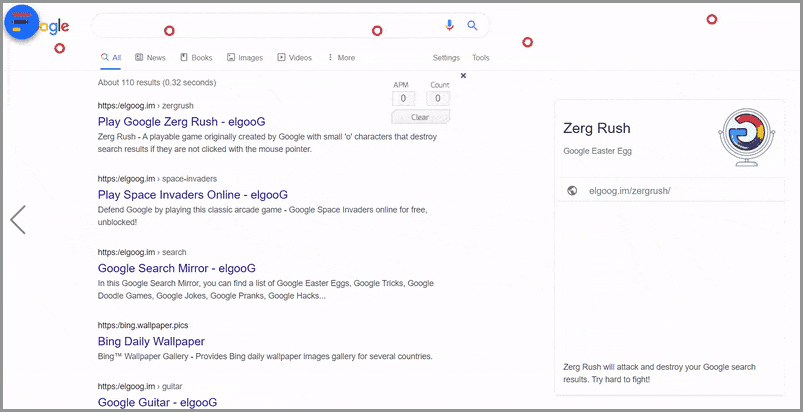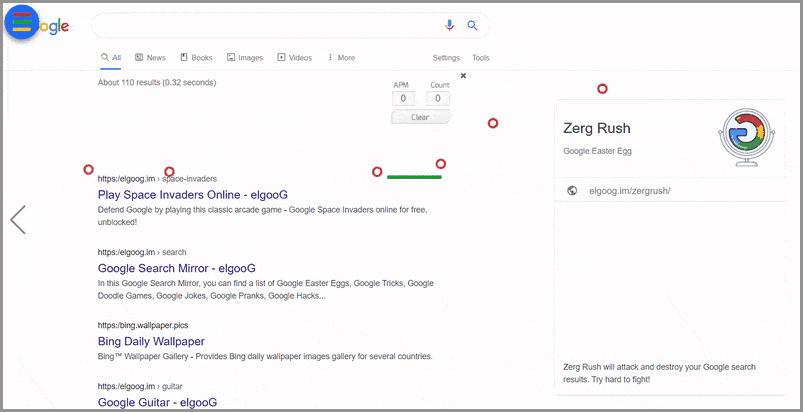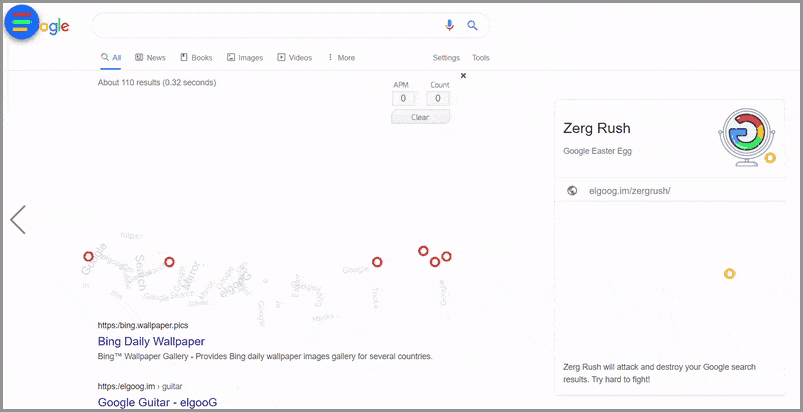
今日アクセスするには、Googleのホームページにアクセスして「zergrush」と入力し、[ I'mFeelingLucky ]ボタンをクリックします。 Googleの以前のイースターエッグをすべて保持しているGoogleのミラーリングされたWebサイトであるelgooGにリダイレクトされます。
このGoogleのトリックをトリガーする方法: zerg rush
1998年のGoogle
Googleが1998年に設立されたとき、検索エンジンのデザインは現在のデザインとは大きく異なります。 たとえば、元のロゴは洗練されたものではなく、Yahoo!に一致する感嘆符が含まれていました。 ロゴ。
Googleが初期の頃の様子に興味がある場合は、Googleが多くのSERP機能の展開を開始する前に、検索バーに「Google in 1998」と入力して、Enterキーを押してください。 このイースターエッグは、検索エンジンの15歳の誕生日を祝うためにGoogle検索に含まれていました。
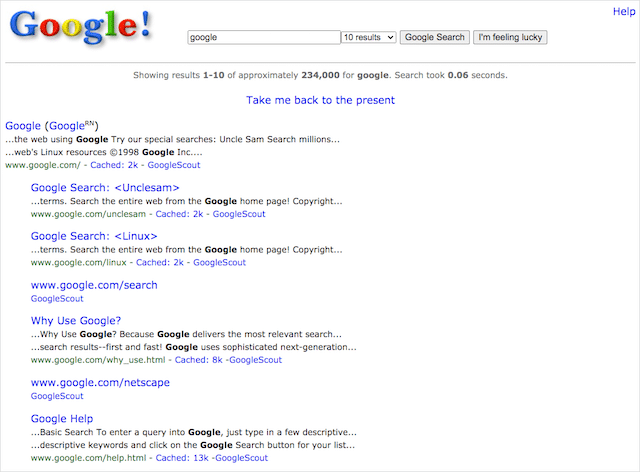
このノスタルジックなバージョンのGoogleで実際の検索を実行することはできませんが、Googleが何年にもわたってどのように変化したかを見るのは楽しいことです。 グーグルはページの下部に1998年頃の検索エンジンのリストさえ持っています。
このグーグルトリックをトリガーする方法: 1998年のグーグル
HTMLを点滅
コーディングに感謝していますか? 次に、Googleの点滅するイースターエッグを気に入るはずです。 Google検索に「blinkhtml」と入力すると、イースターエッグがトリガーされ、「blink」と「html」という単語が点滅するテキストに変わる検索結果が返されます。
Googleの検索結果で点滅するテキストを作成するために使用できる他の用語は、<blink>とblinktagです。
このGoogleトリックをトリガーする方法: blink html
アタリブレイクアウト
Atari Breakoutの37周年の一環として、Googleはこの楽しみに参加し、検索ページ用にイースターエッグをリリースすることを決定しました。 検索ユーザーは、「atari breakout」を検索し、[画像]タブをクリックすることで、このクラシックなビデオアーケードゲームをGoogle検索で直接プレイできます。
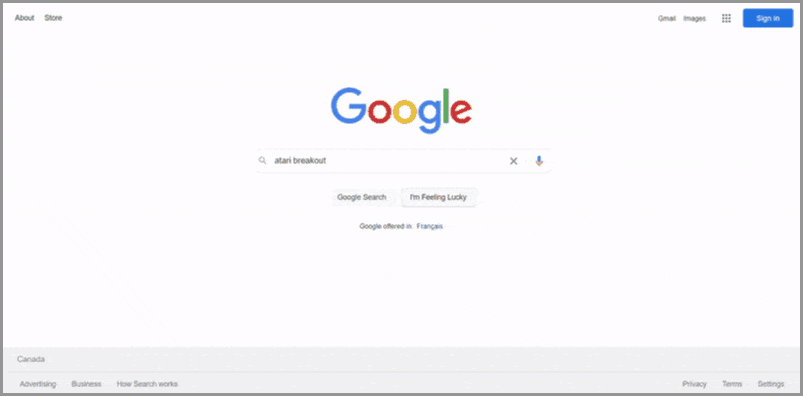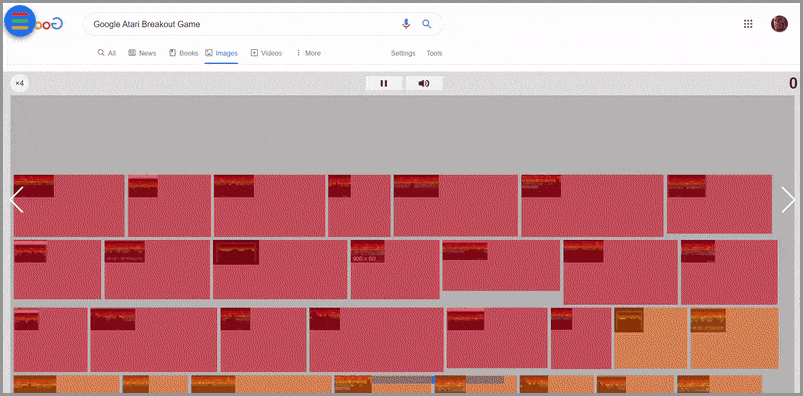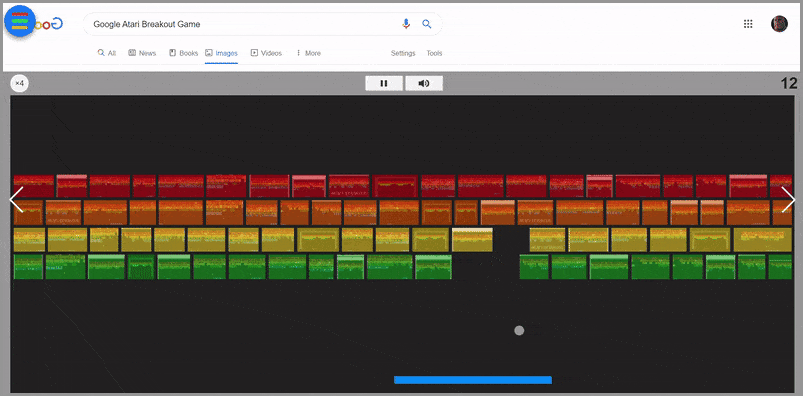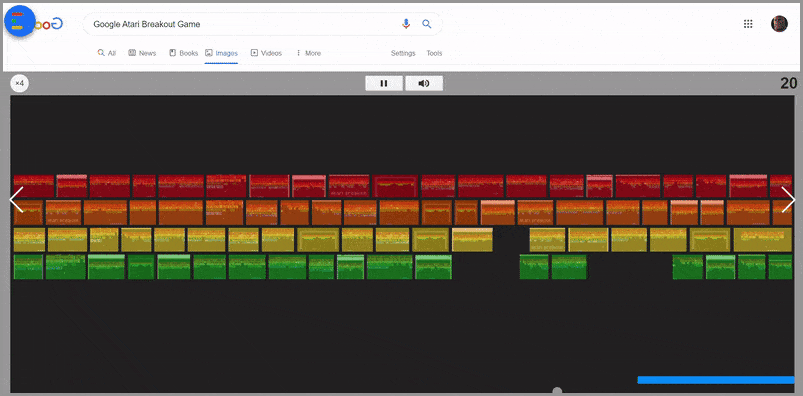
残念ながら、検索用語「atari breakout」は、「zerg rush」と同様に、Googleによって非推奨になりました。 このポンスタイルのゲームを今日プレイするには、Googleのホームページにアクセスし、「atari breakout」と入力して、[ I'mFeelingLucky]をクリックする必要があります。
このGoogleトリックをトリガーする方法: atari breakout
秘密の言語
エルマーファッド、クリンゴン、パイレーツ、リートランゲージ、マペットショーのスウェーデン人シェフの共通点は何ですか?
これらは、Googleがユーザーに提供する架空の言語です。
これらの架空の言語のいずれかを検索設定の優先言語として設定するには、Googleの右上隅に移動し、[アカウント]>[データとパーソナライズ]>[言語]を選択します。 [ +別の言語を追加]ボタンをクリックして、目的の架空の言語を入力します。
別の隠された架空の言語であるPigLatinがありますが、これはアカウントの設定からはアクセスできません。
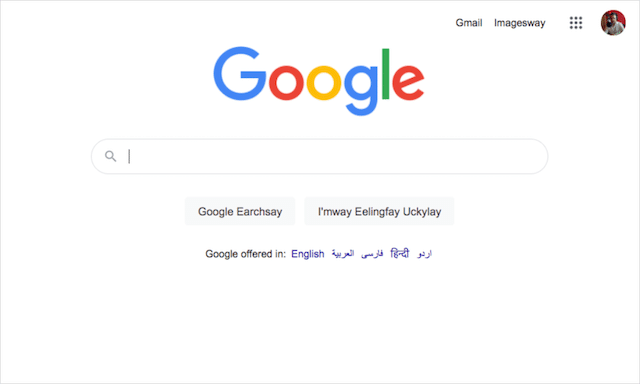
Pig Latin言語インターフェースを試すには、ブラウザのアドレスバーに「www.google.com/?hl=xx-piglatin」と入力します。
パックマン
もう1つの古典的なアーケードゲームであるパックマンは、 1980年12月に最初に世界にリリースされました。40年以上後、Googleはパックマンドゥードルでこの愛されているビデオゲームの古典に敬意を表し続けています。
クラシックゲームのGoogleにインスパイアされたバージョンのプレイを開始するには、検索バーに「pac-man」、「play pac-man」、または「googlepac-man」と入力してEnterキーを押します。 インタラクティブな注目のスニペットが表示され、SERPで直接再生できるようになります。
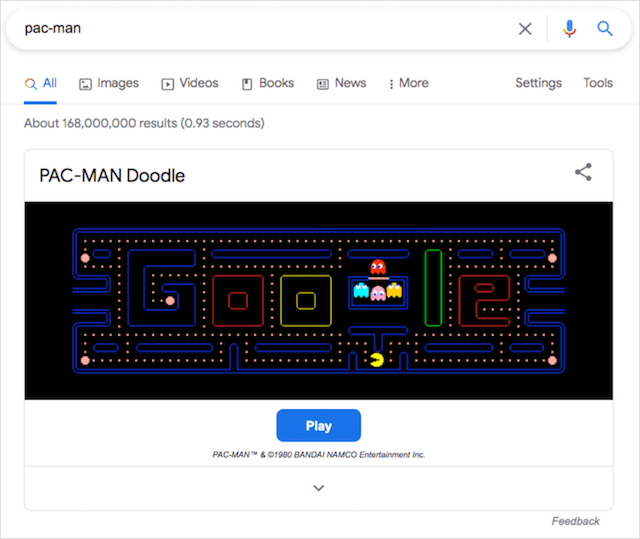
矢印キーを使用して、同名のキャラクターを制御します。
このGoogleのトリックをトリガーする方法: pac-man
人生への答え
ダグラス・アダムズの 『銀河ヒッチハイカーガイド』のファンなら誰でも、「人生、宇宙、そしてすべての究極の問題への答え」が42であることを知っているでしょう。数字42の深い象徴的な意味。
42という数字に特別な意味があるかどうかにかかわらず、Google独自の「スーパーコンピューター」は、アダムズの人生の本当の意味のバージョンと一緒にプレイすることを決定しました。 「人生、宇宙、そしてすべてへの答え」と入力すると、Google検索は42で応答します。
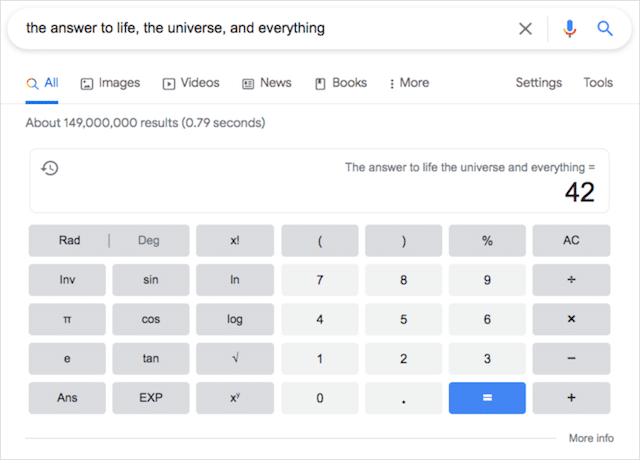
このGoogleのトリックをトリガーする方法:人生、宇宙、そしてすべてへの答え
チャックノリスを探す
インターネットミームのファンは、チャックノリスの事実、武道家で俳優のチャックノリスに関する風刺的な(そしてしばしば誇張された)ファクトイドのリストについてすべて知っているでしょう。
チャックノリスファクトのいくつかの顕著な例は次のとおりです。
- チャックノリスはゼロ除算できます。
- チャックノリスは眠りません。 彼は待っています。
- チャックノリスは無限に数えました…2回。
- チャックノリスは雨の中から雪だるまを作ることができます。
- チャックノリスは角氷で火を起こすことができます。
グーグルは、チャック・ノリスを彼らの隠されたイースターエッグの1つとして含めることによって、このインターネット現象と一緒に遊ぶことに決めました。
Googleのホームページに「チャックノリスを探す」または「チャックノリスはどこですか」と入力して[I'mFeelingLucky]をクリックすると、Googleは検索結果を返したり、ウェブサイトに移動したりしません。
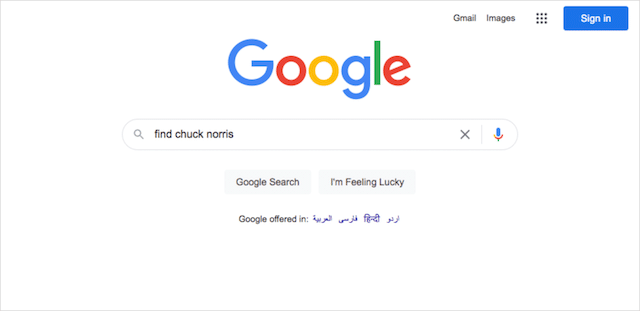
それは、不条理な双曲線の主張が行くように、「チャック・ノリスを見つけられないからです。 彼はあなたを見つけます。」
このGoogleのトリックをトリガーする方法:チャックノリスを見つける
コインをはじく
「コイントス」を検索するもう1つの気の利いた視覚的機能により、コイントスゲームがGoogleのオーガニックリストの上に表示されます。 検索バーのEnterをクリックすると、コインが自動的に反転します。
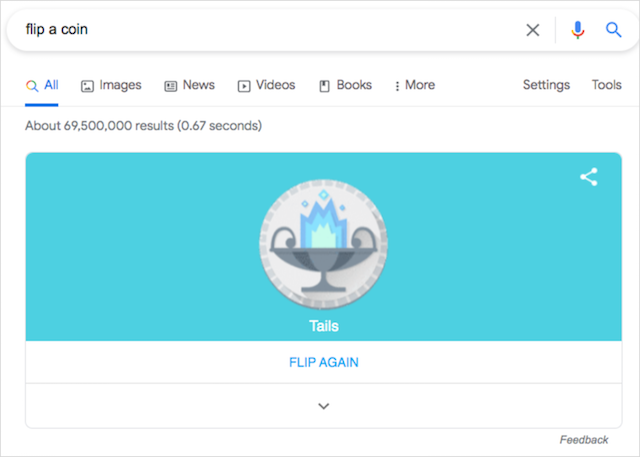
コインをもう一度裏返すには、 FLIPAGAINテキストをクリックするだけです。
このGoogleのトリックをトリガーする方法:コインを投げる
サイコロを振る
コインを投げるよりもサイコロを振るのが好きなら、Googleはあなたのためにイースターエッグを持っています。 このGoogleのトリックのロックを解除するために必要なのは、「サイコロを振る」または「サイコロを振る」を検索することだけです。 Googleは、6面から20面のサイコロまで、複数の面から選択できるサイコロも提供しています。
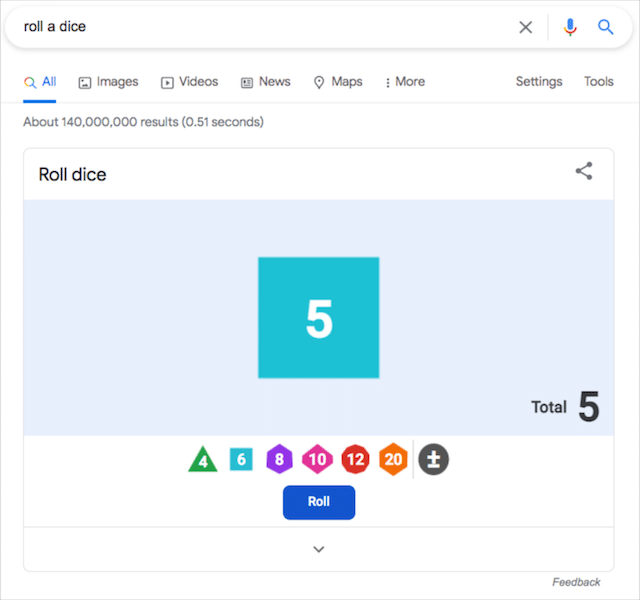
ユーザーはサイコロの組み合わせを選択することもでき、サイコロのイースターエッグを完全にカスタマイズできます。

このGoogleのトリックをトリガーする方法:サイコロを振る
ヒント電卓
Googleがユーザーに提供するグラフ電卓のイースターエッグは「42」だけではありません。 Googleは、ユーザーが検索結果から直接請求額のチップをすばやく計算できるようにすることもできます。 電卓は一人当たりのチップの合計量を分割することもでき、楽しい夜の外出に便利な機能になります。
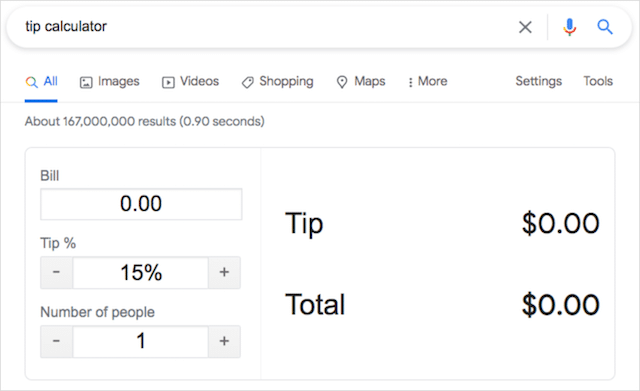
あなたがグーグルを通して試すことができる他の計算機のイースターエッグは次のとおりです:
- ユニコーンの角の数
- 最も孤独な数は何ですか
- 一度ブルームーンで
このGoogleのトリックをトリガーする方法:チップ計算機
アレックストレベック
ゲーム番組JeopardyのホストであるAlexTrebekが2020年に亡くなったとき、Googleは、検索結果ページに特別なJeopardyトリビュートを含めることで、ゲーム番組の司会者を称えることにしました。 トレベックの名前を検索すると、Googleは「アレックストレベックとは誰か」を提案して検索語を修正します。
これは、ジェパディのルールへの感動的な参照です。ここでは、競技者は「誰が」または「何が」の応答でゲームの手がかりに答える必要があります。
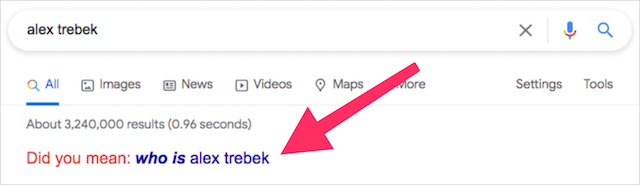
このGoogleのトリックをトリガーする方法: alex trebek
スーパーマリオブラザーズ。
もう1つの古典的なビデオゲームであるスーパーマリオブラザーズは、1985年に日本のファミコンと米国のファミコン(NES)向けに最初にリリースされました。 それ以来、スーパーマリオブラザーズは最も成功したビデオゲームフランチャイズの1つになりました。
スーパーマリオブラザーズの名高い遺産を認め、Googleはマリオをテーマにしたイースターエッグを検索結果ページに直接含めました。 「スーパーマリオブラザーズ」と入力すると、「?」が点滅するスーパーマリオブラザーズのナレッジパネルが表示されます。 ブロック。
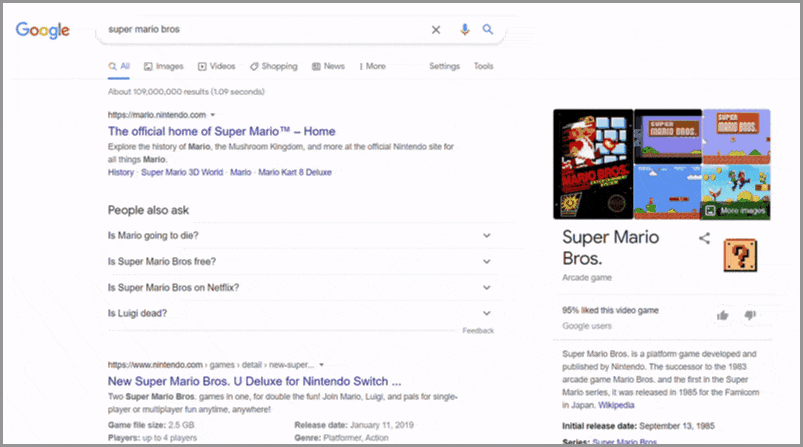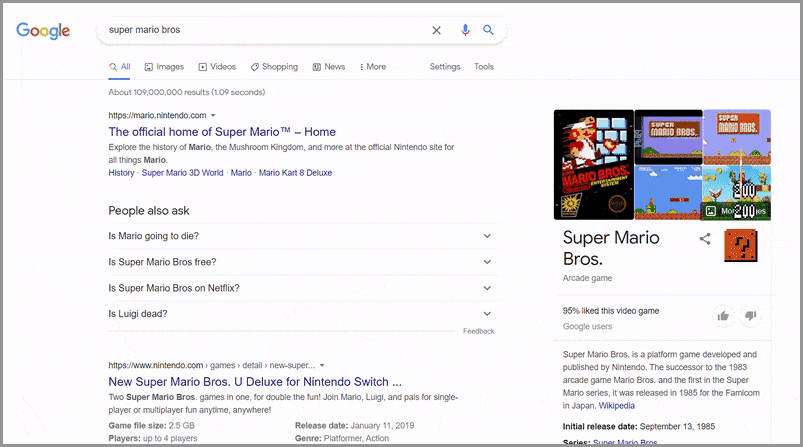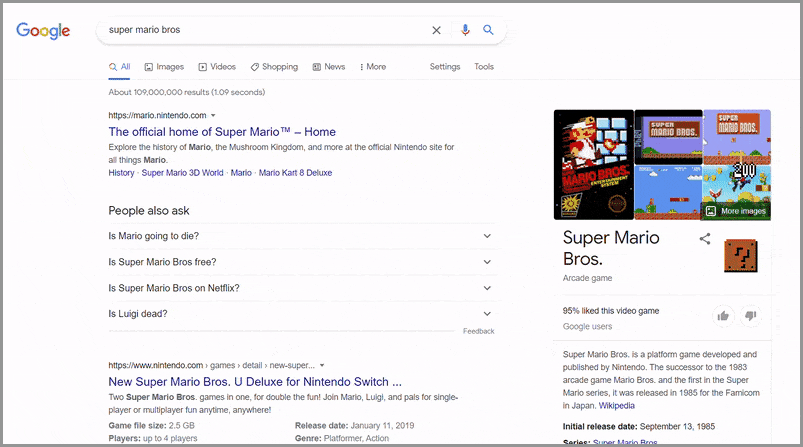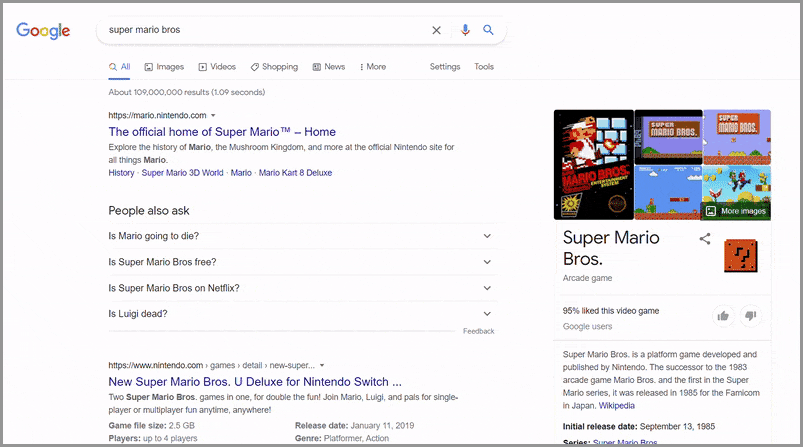
このきらびやかなボックスはゲーム内のリファレンスであり、プレイヤーはブロックを叩いてコインを獲得できます。 また、ビデオゲームと同様に、Googleの検索結果でコインボックスをクリックすると、200ポイントが付与され、スーパーマリオブラザーズゲームと同じコイン効果音が生成されます。
また、ゲームと同じように、ボックスを何度もクリックして100コインを集めると、1-UPサウンドがもらえます。
もう1つの古典的なビデオゲームであるSonictheHedgehogも、ナレッジパネルに独自のアニメーションGIFを持っています。 待っているソニックをクリックすると、彼はスピンします。 数回クリックすると、SonicがSuperSonicに変換されます。
このGoogleトリックをトリガーする方法:スーパーマリオブラザーズ/ソニックザヘッジホッグゲーム
ラッキーな気分です
Googleは、特別なイベント、休日、または著名な歴史上の人物を記念して、ロゴを編集することがよくあります。 Googleのロゴに対するこれらのユニークで一時的な変更は、Google Doodleと呼ばれ、1998年からGoogleのホームページに表示されています。
これらの特別なロゴ編集のいずれかを見逃したり、作成されたすべてのGoogle Doodleを確認したい場合は、Googleのホームページにアクセスし、検索バーに何も入力せずにI'mFeelingLuckyをクリックしてください。
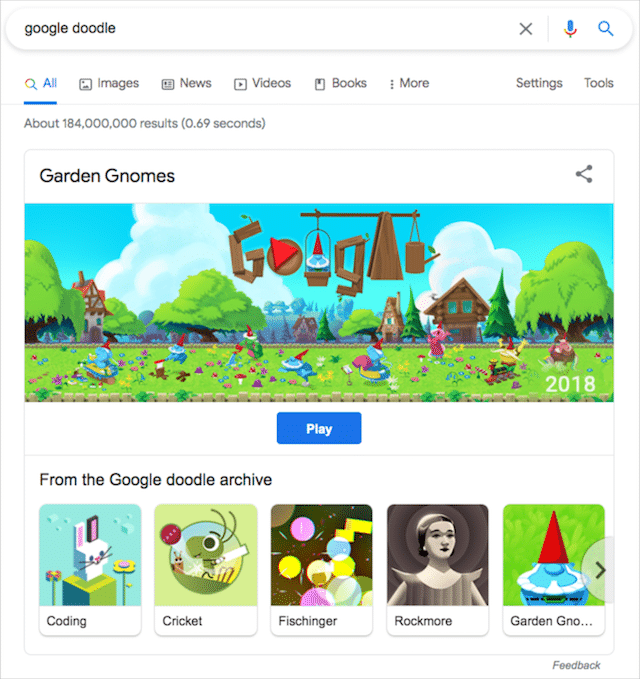
これにより、Google Doodleアーカイブにリダイレクトされます。ここでは、これまでに作成されたすべてのロゴバリエーションを確認し、GoogleDoodleの歴史について詳しく知ることができます。 ランダムなインタラクティブなGoogleDoodleを検索結果に直接表示するには、「googledoodle」と入力します。
このグーグルトリックをトリガーする方法:グーグル落書き
Google検索演算子を最大限に活用するための15の方法
上記のすべての検索コマンドは、Googleの検索スキルを基本的なGoogle社員から検索の原動力に変えるのに役立ちます。 ただし、これらの検索演算子をさらに活用するには、それらを組み合わせて利点を生かす方法を知っておく必要があります。
幸いなことに、私は15の生産性向上ツールのリストをまとめました。これにより、検索機能が楽しいトリックや通常のテキスト検索を超えてGoogleの習得に向けて向上します。
(1)。 多数の演算子を組み合わせる
検索演算子に関しては、組み合わせは無数にあります。
使用するコマンドの種類は、検索要件と想像力にのみ依存します。
たとえば、リンク構築の機会、つまりリンクの切り上げを通じてコンテンツを共有することを探している場合は、次の一連の検索演算子を使用して検索を絞り込むことができます。
【キーワード】「リンクまとめ」
このGoogle検索修飾子の組み合わせと、キーワード「コンテンツマーケティング」を使用すると、23,400件の結果が得られます。
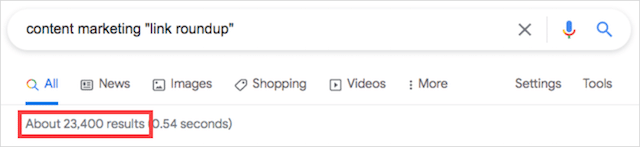
ただし、次のような「intitle:」または「inurl:」検索演算子を使用すると、検索をさらに絞り込むことができます。
[キーワード]intitle:” roundup” inurl:” round-up”
今、私は394の結果になりました:
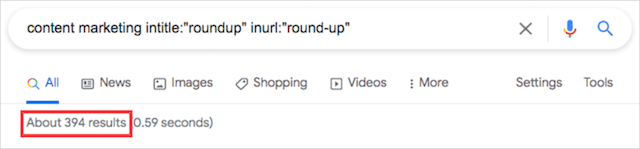
悪くない!
それでも、結果を特定のTLDに制限することで、リンクの切り上げ検索をさらに絞り込むことができます。
そのために、「site:」演算子を論理ORコマンドと組み合わせます。
[キーワード]intitle:” roundup” inurl:” round-up”(site:comまたはsite:org)
そして今、私はたった6つの結果になりました:
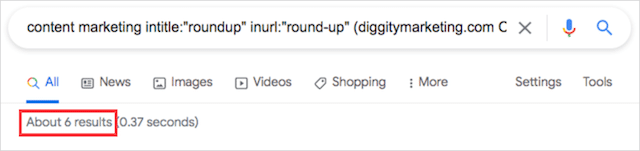
あなたはポイントを取得します。
検索文字列で組み合わせる検索演算子が多いほど、検索はより洗練されたものになります。
(2)。 検索演算子を使用した重複コンテンツの検索と削除
サイト内の複数のURLに同じコンテンツが表示されると、コンテンツの重複の問題が発生する可能性があります。 グーグルのような検索エンジンが重複したコンテンツを見るとき、それらはバージョンを区別するのに苦労します。
サイト所有者として、これは次のことを意味します。
- リンクメトリクス(リンクエクイティなど)の希薄化により、ランキングが失われる
- 検索の可視性が低下し、トラフィックが失われる
場合によっては(まれですが)、コンテンツが重複していると、サイトのインデックスが検索エンジンから削除される可能性があります。
重複するコンテンツの問題がないかサイトを再確認するには、「site:」および「intitle:」検索演算子を使用できます。
site:yourdomainname.com intitle:「重複するタイトルの疑いがここにあります」
この例を使用すると、ドメイン全体で正確な(または類似の)コンテンツでページが複製された結果を返すことができます。
Farfetchドメインを検索したときに見つけた1つの例を次に示します。

そして、あなたが見ることができるように、これらのページはまったく同じです:

さらに、「intitle:」を「intext:」に置き換えると、Webサイト内で繰り返されているコンテンツのパッセージ全体を見つけることができます。 特定のGoogle検索構文は次のとおりです。
site:yourdomainname.com intext:「重複したテキストの疑いがここにあります」
Farfetchの重複コンテンツの問題を深く掘り下げて、両方のページで使用されている製品の説明をコピーしました。
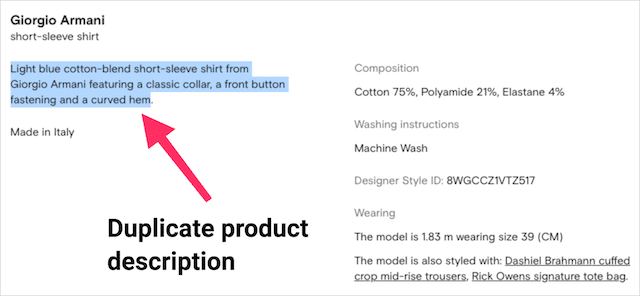
検索文字列に貼り付けました。
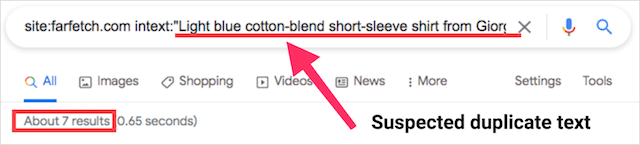
そして、テキストが7ページにわたって繰り返されていることがわかりました。
重複するコンテンツは、eコマースサイトの大きな問題です。
多くのサイトには、数万とは言わないまでも数千の製品があります。
したがって、eコマースストアを運営している場合は、これらの検索演算子をテストして、Webサイトに存在する可能性のある重複するコンテンツページを見つけるのに役立てることをお勧めします。
補足:重複コンテンツの問題があるeコマースサイトについては、URLスラッグガイドをご覧ください。 異なるURL間で同じコンテンツを提供してはならない理由と、重複するURLの問題に対処するためにできることについて説明します。
しかし、重複するコンテンツは、Webサイトだけに存在するわけではありません。 一部のサイトでは、ランキングを一掃するためにコンテンツをコピーする場合があります。
次の実用的なヒントは、盗用の問題に対処するのに役立ちます。
(3)。 検索演算子を使用してコンテンツの盗用を追跡する
ウェブ上に2つの同一のドキュメントがある場合、GoogleはPageRankが高い方を選択し、検索結果で使用します。

つまり:
あなたのドメインが新しくて弱い場合、あなたはコンテンツを投稿し、それが盗まれた場合、あなたはあなた自身の(盗用された)記事によってランク付けされるかもしれません。
ご想像のとおり、驚くべきSEOコンテンツを作成する作業を行っており、そのコンテンツがコピーキャットのヘビーウェイトよりも上位にあることがわかった場合、それは非常に苛立たしいことです。
幸いなことに、この検索演算子を使用すると、盗用の犯人を簡単に見つけることができます。
intitle:「盗用された疑いのあるコンテンツ」-site:yourdomainname.com
引用符付きの「intitle:」演算子を使用すると、Googleは完全に一致するタイトルの結果のみを返すようになります。 検索に「-site:」コマンドを含めることにより、結果に表示したくないサイトを除外します。
この場合、これはコンテンツの発信者であるため、独自のドメインです。
たとえば、SEO実験に関するJamesの投稿を使用してこの検索を実行すると、8つの重複するバージョンが見つかります。
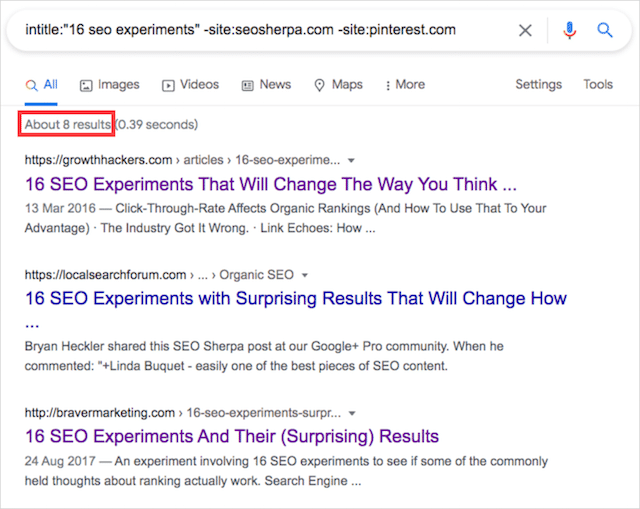
ありがたいことに、SEO Sherpaはこのキーワードでトップにランクされており、各ページはソースとしての投稿にリンクしています。
しかし、そうでない場合は、これらのサイトに連絡して、コンテンツを削除するか、投稿に「rel=canonical」を追加するように依頼することができます。
補足: pinterest.comも除外していることに気付くでしょう。 これは、クエリのPinterestの結果が多かったため、結果をさらに絞り込みたかったためです。 除外できるドメインの数に制限はありません。
もちろん、あなたのブログ投稿のページタイトルをコピーしただけの誰かが、必ずしも完全な盗用を示しているわけではありません。 テキストのブロックが知らないうちに大量にコピーされたことを再確認するには、「intext:」および引用符(」「)コマンドを使用します。 外観は次のとおりです。
intext:「盗用された疑いのあるコンテンツ」-site:yourdomainname.com
以下に示すように、Jamesの投稿からのパッセージで「intext:」演算子を使用すると、さらに多くの結果が返されます。
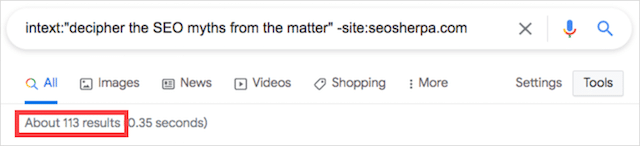
引用符と「intext:」コマンドはどちらも同様の機能を実行します。
ただし、「intext:」演算子は引用符よりも微妙な違いがあり、より大きな結果が得られる可能性があります。 結局のところ、すべての盗作者があなたのページタイトルを複製に含めるわけではありません。
そうは言っても、両方を試す価値は十分にあります。
(4)。 検索演算子を使用してキーワードの難易度を評価する
Googleの最初に表示される圧倒的多数のページには、タイトルタグでランク付けされたキーワードが含まれています。
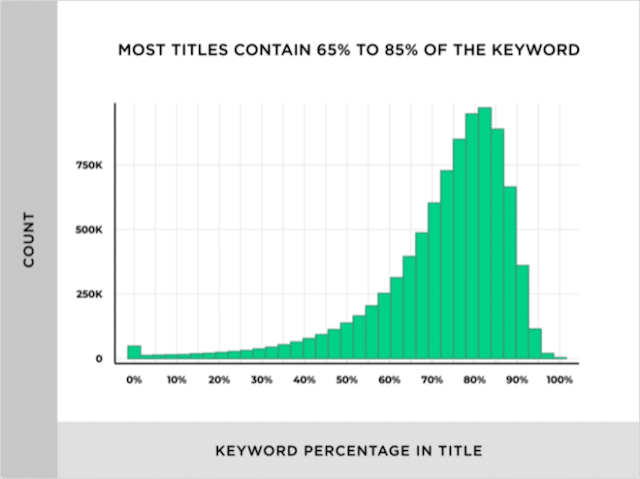
つまり、キーワードのランク付けが簡単(または難しい)かどうかを知りたい場合は、タイトルタグでそのキーワードをターゲットにしているページ数を知ることが特に便利です。
「allintitle:」検索演算子を入力します。
名前が示すように、「allintitle:」演算子は、指定されたすべてのキーワードがタイトルタグに含まれている結果を表示します。 コマンドを使用するには、 allintitleと入力するだけです。チェックするキーワードフレーズの後に続きます。
次に例を示します。
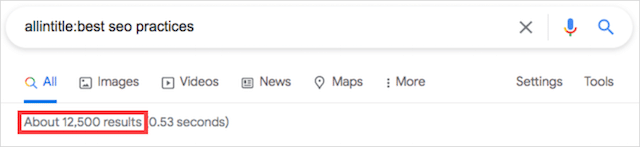
そして、allintitleの別の例:演算子:
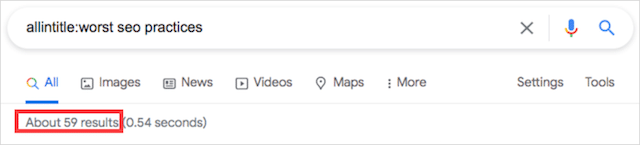
ご覧のとおり、私の例のキーワードは似ていますが、それぞれに返される結果の数は大きく異なります。
投稿を書くことを考えていて、すばやく簡単なランキングが必要な場合は、2番目のキーワードを選択します。
そのキーワードを積極的にターゲットにしているのは59ページだけなので(「ベストSEOプラクティス」の場合は12,500に対して)、ランキングの可能性ははるかに高くなります。
(5)。 Google AdvancedSearchOperatorsでのインデックス作成の問題の検索と対処
ウェブサイトのインデックスを作成することは、検索エンジンに表示するための重要な最初のステップです。
ページがインデックスに登録されていない場合、ランク付けできません。 ページがインデックスに登録されているが適切にインデックス付けされていない場合は、検索の可視性が低く、ランキングが低いことを期待してください。
ドメインのすべてのインデックス付きページを表示する基本的な検索演算子は、 site:コマンドです。
seosherpa.comのルートドメインを検索すると、site:演算子が返すものは次のとおりです。
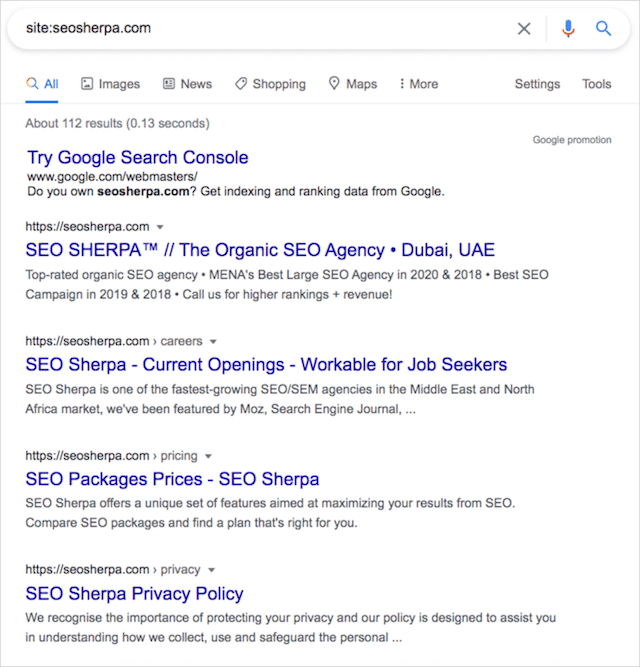
それはグーグルがドメインのために索引付けされた112ページを持っていることを明らかにします、そしてそれはほぼ正しいように見えます。
当社のウェブサイトの実際のページ数とGoogleのインデックスのページ数の間に大きな不一致があった場合、これは調査の原因となります。
同じ検索演算子を使用して、特定のページがインデックスに登録されているかどうかを確認することもできます。 これを行うには、ドメインだけでなく、それぞれのスラッグを含む完全なURLを使用します。
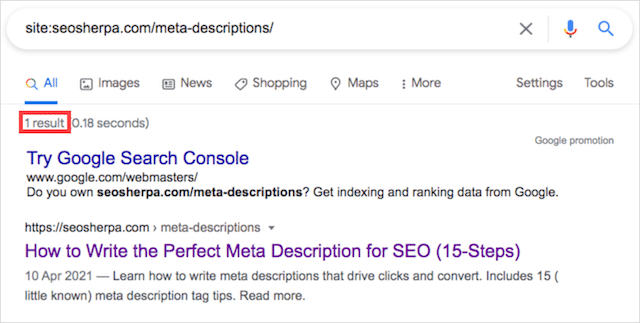
この基本的な検索演算子は、公開後にページがインデックスに登録されているかどうかを確認するのに役立ちます。
単一サイトの検索演算子以外にも、インデックス作成の問題を監査するのに役立つ検索演算子の組み合わせがあります。
安全でないページを探す
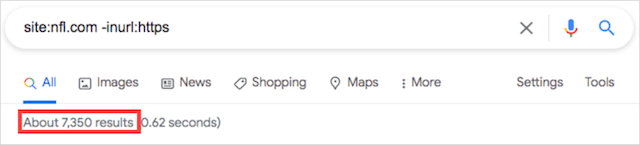
最近サイトをHTTPからHTTPSに移行した場合は、「site:」コマンドと「inurl:」コマンドを組み合わせて、不正な非セキュア(HTTP)ページについてWebサイトを監査できます。 外観は次のとおりです。
site:yourdomainname.com -inurl:https
例が示すように、URLにHTTPSが含まれているサイトのWebページを省略するには、必ず「inurl:」演算子の前に除外コマンド「-」を含めてください。
上記の検索演算子を使用してNationalFootballLeague(NFL)を検索したところ、Googleは7,350ページの安全でないページを返しました。
Webサイトが安全なhttpsプロトコルを使用しているにもかかわらず、次のようになります。

それが問題です。
サブドメインを探す
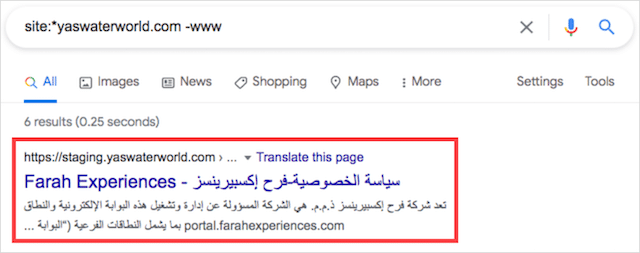
インデックス作成の問題を見つけるために使用できる別の検索演算子の組み合わせは次のとおりです。
サイト:*。yourdomainname.com -www
「site:」検索語にワイルドカード(*)演算子を含めることで、ドメイン内に存在するすべてのサブドメインを見つけることができます。 除外(-)コマンドは、URLにwwwを含むドメイン結果をすべて削除します。
この検索演算子の組み合わせは、Googleでインデックスに登録された不正なサブドメインを特定するのに役立ちます。
たとえば、Yas Water Worldでこの検索演算子を実行すると、コンテンツの重複の問題を回避するためにインデックスなしのタグを追加する必要があるステージングWebサイトが見つかりました。
これらのインデックスチェッカーを自分のWebサイトでテストしてください。 あなたはあなたが見つけたものに驚くかもしれません。
(6)。 検索演算子を使用してサイト上の忘れられたファイルを追跡する方法
ファイル検索の実行方法を知っていると便利です。
それは何年にもわたってあなたのウェブサイトで忘れられている未使用または古いファイルを見つけるのを助けることができます。
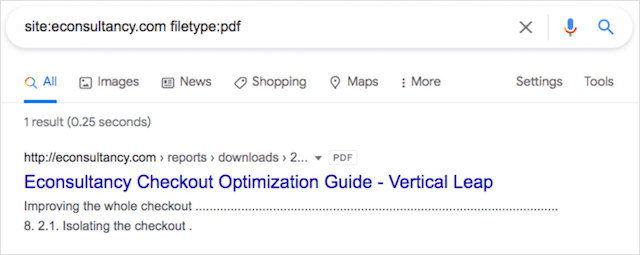
Webサイトで確認する必要がある最も一般的なファイルタイプの1つは、PDFファイルです。
site:yourdomainname.com filetype:pdf
ただし、「filetype:」コマンドを使用すると、ドメイン内に隠されているあらゆる種類のファイルを検索できます。
PDFの他に、Googleがインデックスを作成してサポートするすべてのファイルタイプのリストを次に示します。
- Adobe Flash(.swf)
- Adobe Portable Document Format(.pdf)
- Adobe PostScript(.ps)
- Autodesk Design Web Format(.dwf)
- Google Earth(.kml、.kmz)
- GPS交換フォーマット(.gpx)
- Hancom Hanword(.hwp)
- HTML(.htm、.html、その他のファイル拡張子)
- Microsoft Excel(.xls、.xlsx)
- Microsoft PowerPoint(.ppt、.pptx)
- Microsoft Word(.doc、.docx)
- OpenOfficeプレゼンテーション(.odp)
- OpenOfficeスプレッドシート(.ods)
- OpenOfficeテキスト(.odt)
- リッチテキスト形式(.rtf)
- スケーラブルベクターグラフィックス(.svg)
- TeX / LaTeX(.tex)
- テキスト(.txt、.text、その他のファイル拡張子)
- 基本的なソースコード(.bas)
- C / C ++ソースコード(.c、.cc、.cpp、.cxx、.h、.hpp)
- C#ソースコード(.cs)
- Javaソースコード(.java)
- Perlソースコード(.pl)
- Pythonソースコード(.py)
- ワイヤレスマークアップ言語(.wml、.wap)
- XML(.xml)
「filetype:」コマンドを「ext:」演算子に置き換えることもできます。 どちらも交換可能で、同じタスクを実行します。
Econsultancyのドメインでこれらの検索コマンドを使用して、私が見つけたものは次のとおりです。
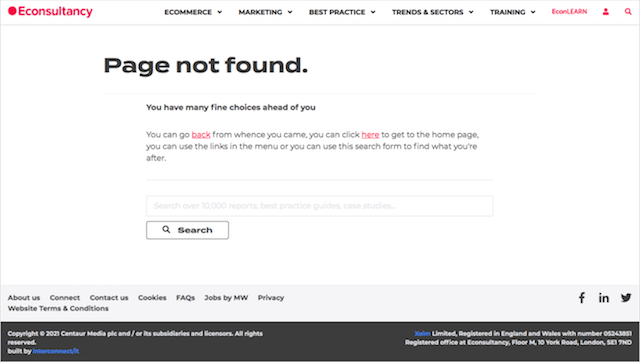
リンクをクリックすると、404エラーが返されました。これは、Econsultancyのウェブマスターが検索結果に表示されたくないと確信しているためです。
たとえば、複数のファイルタイプを同時に使用することもできます。
site:yourdomainname.com(filetype:pdfまたはfiletype:docx)
この検索クエリは、PDFおよびMicrosoftWord拡張子を持つ特定のドメイン上のすべてのファイルを検索します。
電子書籍やガイドなどのゲートコンテンツがGoogleのインデックスに登録されているかどうかを確認する場合に非常に便利です。
それでは、不要なファイルタイプの検索から、コンテンツマーケティング戦略の改善に移行しましょう。
(7)。 「Filetype:」演算子を使用して、不足しているコンテンツの機会を見つけます
「filetype:」検索演算子の汎用性は、コンテンツマーケティング戦略をサポートするためにも使用できることを意味します。
サイトの規模やドメインの年齢によっては、PDFやWordドキュメントなど、検索に最適化されていない形式で、サイトの奥深くに隠されている古いが関連性の高いコンテンツがある場合があります。
Andy Crestodinaが指摘しているように、PDFファイルはあなたのサイトの「さび」であり、偶然に検索エンジンでランク付けされるだけです。

「本格的な検索オプティマイザーは、PDFファイルで競合するフレーズをターゲットにすることを推奨しません。」
Word文書は、PDFファイルと同じくらい悪いですが、悪くはありません。 Wordドキュメントは検索用に最適化できないだけでなく、ウイルスが含まれている可能性があるため、開くのも危険です。
したがって、これらのファイルのいずれかがWebサイトに隠されている場合、「site:」および「filetype:」検索を実行すると、それらをランクに値するHTMLコンテンツに変換する機会を特定するのに役立ちます。
(8)。 検索演算子を使用して、関連するリンク構築の機会を見つける
リンク構築の専門家は、多くの場合、有料ツールを使用してリンクプロスペクティングの取り組みを強化することを推奨しています。
そして、私はSEOツールをノックするためにここにいるわけではありませんが(私たちは独自のSEOサービスを提供するためにいくつかを使用しています)、ソフトウェアは多くの中小企業にとって予算外です。
では、限られたリソースで関連するリンク構築の機会をどのように見つけることができますか?
もちろん、検索演算子を使用します。
リンク構築の取り組みに役立つあまり知られていない検索コマンドの1つは、次のとおりです。
関連:webaddress.com
「related:」演算子は、演算子に記載されているWebサイトに類似したドメインを見つけるのに役立ちます。
あなたがあなたのリンク構築キャンペーンに関連するウェブサイトを見つけようとしているなら、本当に便利です。
例えば:
Hubspotのブログページに関連する同様のサイトを検索すると、32件の結果が返されます。
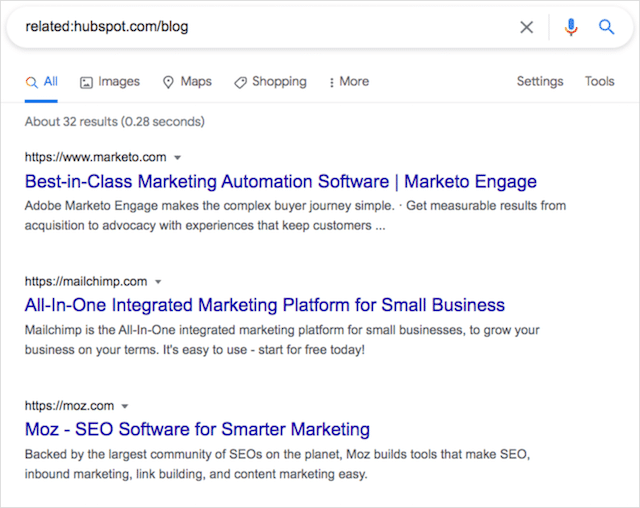
これは、他の方法では見つけられなかった可能性のある非常に多くの機会です。
すばらしいのは、検索演算子を使用して、トピックの関連性の機会を精査することもできることです。
Ahrefsは、この公式の概要を説明しています。これは非常にうまく機能します。
- 結果のリストからターゲットとするドメインを選択します。
- 「site:」クエリを実行し、検索結果の数をメモします。
- 「site:」クエリに[niche]検索を追加し、その結果の番号をメモします。
- 2つの数字を割ります。
関連する見込み客と見なされるには、2つの数値の商を0.5以上にする必要があります。 結果が0.75を超える場合、リンクの見通しは非常に関連性があります。
つまり、このプロセスでは、ターゲットWebサイトのニッチな関連コンテンツの比率を測定します。 商が高いほど、Webサイトの関連性が高くなります。
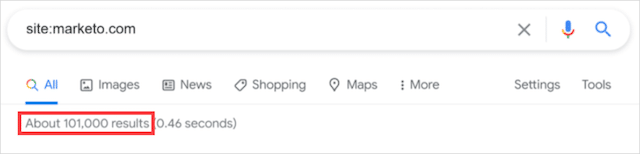
Hubspotの例の一番上の結果でこれを試してみましょう。
まず、「site:」検索を実行します。
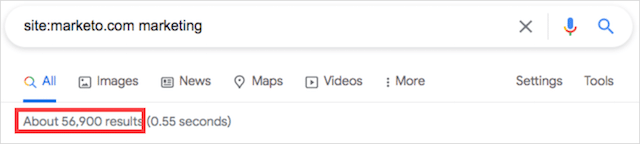
次に、ニッチをクエリに追加します。
結果から2つの数値が得られたら、次のように2つの数値を除算します。
56,900 / 101,000 =〜0.56
ご覧のとおり、MarketoはHubspotの有望な候補です。
もちろん、リンクの見込み客を見つけるために検索オペレーターだけに頼らないでください。
Ahrefsの式は、無関係なリンクの見込み客を排除するための優れた方法ですが、連絡する前に、見込み客のサイトを手動で確認することをお勧めします。
リンクプロスペクティングは、検索オペレーターの唯一のリンク構築機能ではありません。 ゲスト投稿の機会に検索演算子をどのように使用できるかを見てみましょう。
(9)。 検索オペレーターを活用してゲストのブログサイトを見つける
これらすべての年月を経ても、リンク構築の実践としてのゲスト投稿は異なる意見で見られています。 ゲスト投稿を完全にサポートするものもあれば、それを避けているものもあります。
検索オペレーターでゲスト投稿の機会を見つける方法を明らかにする前に、Googleがゲスト投稿について実際に何を言っているかを見てみましょう。
Search Engine Journalは、Googleがいくつかの記事でゲスト投稿を公開しているサイトにペナルティまたは手動アクションを与えていると述べています。
John Muellerは、ゲスト投稿に対するGoogleの姿勢を明確にし、Googleはゲスト投稿内のリンクの価値を下げていると述べています。
つまり、ゲストの投稿を完全に無視する必要があるということですか?
絶対違う。
SEO業界の多くの人が指摘しているように、ゲストの投稿は、特に関連性が高く高品質のWebサイトをターゲットにしている場合、ブランド認知度を高める上で依然として価値があります。 そして、ミューラーは、慣例として、ゲスト投稿ではなく、有料ゲスト投稿を具体的に参照しました。
SEMrushのMelissaFachは、2021年以降のゲスト投稿の作成方法を最もよく要約しています。

では、検索演算子を使用してこれらの関連性の高いサイトをどのように探しますか?
これらのサイトを見つける最も基本的な方法は、「intitle:」コマンドを使用することです。
intitle:” write for us”[ニッチまたはキーワード]
クエリに「inurl:」を含めて、サイトをゲスト投稿の機会としてさらに限定することもできます。
intitle:” write for us” inurl:” write-for-us” [ニッチまたはキーワード]
このクエリは、キーワードまたはコンテンツトピックに関連するライターを探しているサイトを見つけるのに役立ちます。
資格のあるゲスト投稿サイトを見つけるために試すことができるその他の検索用語は次のとおりです。
- 「寄稿者になる」
- 「ゲスト投稿の機会」
- 「コンテンツを送信する」
- 「寄稿者」
- 「投稿を提案する」
- 「寄稿者ガイドライン」
- 「ゲスト投稿ガイドライン」
- 「ゲスト投稿の受付」
これらはそこにある多くの検索用語のほんの一例であるため、使用するフレーズを工夫してください。
専門分野がメールマーケティングの場合、検索結果は次のようになります。
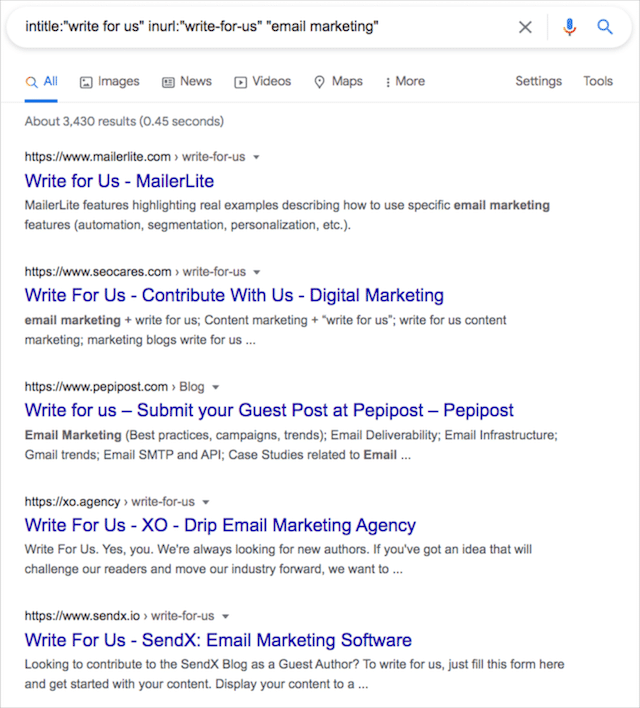
結果をさらに絞り込むために、スピーチマーク( "")にニッチを追加したことに注目してください。
私が行ったように、複数の検索コマンドを試して、ゲスト投稿の機会を見つけてください。
(intitle:” write for us”またはintitle:” contributorになる” OR inurl:” contributor-guidelines”)[ニッチまたはキーワード]
そうすれば、さまざまな機会を見つけることができます。
適切なウェブサイトを見つけたら、そのコンテンツと執筆ガイドラインを注意深く確認してください。 連絡先のブログに関連するコンテンツを作成することを提案していることを確認する必要があります。
事前にこの調査を行わないと、時間と編集者の時間の無駄になります。
ゲスト投稿について説明したので、検索オペレーターを使用して、インフォグラフィックを備えたサイトを見つける方法を見てみましょう。
(10)。 検索演算子を使用して、インフォグラフィックを検索して売り込みます
インフォグラフィックは、コンテンツマーケティングの効果的なビジュアルメディアであり続けます。
インフォグラフィックは、インパクトのある視覚的に心地よい方法で複雑な情報を伝えるための完璧なクリエイティブな手段です。
適切に設計されたインフォグラフィックは、コンテンツを目立たせ、理解しやすくし、読者の心に大きな印象を残すことができます。

しかし、ゲストの投稿のように、韻や理由なしにインフォグラフィックのアウトリーチを単純に爆破することはできません。 あなたのアウトリーチの努力を無駄にしないためにあなたのインフォグラフィックを特色にしたいウェブサイトを見つけるのが最善でしょう。
また、ゲスト投稿と同様に、インフォグラフィックを送信するサイトを見つける最良の方法は、「intitle:」および「inurl:」検索演算子を使用することです。
intitle:infographic inurl:infographic [niche / keyword]
インフォグラフィックに適したサイトをさらに確実に見つけるには、[設定]>[高度な検索]にあるGoogleの組み込みの日付フィルターの使用を検討してください。 結局のところ、2、3年前にインフォグラフィックを大量に公開していたサイトは、ピボットされ、インフォグラフィックを受け入れなくなった可能性があります。
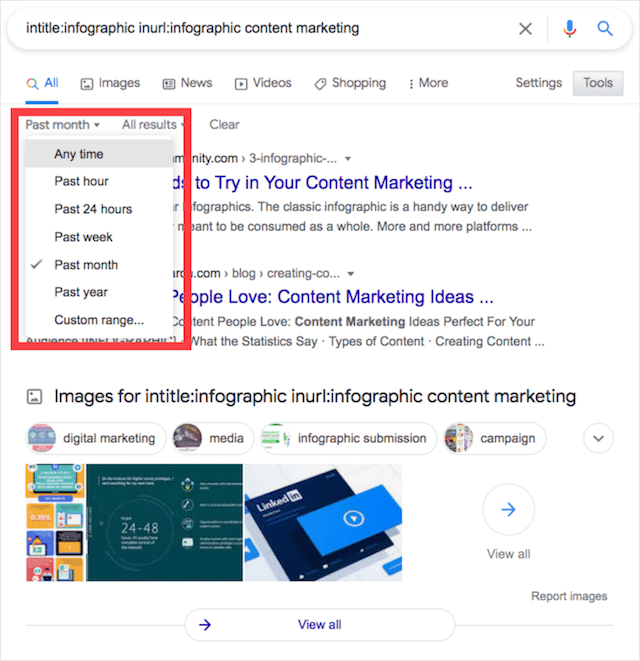
補足:インフォグラフィックをWebサイトに売り込むとき、覚えておくべき主なことは、インフォグラフィックの品質とそれが伝えようとしているメッセージです。 視覚的に説得力があり、専門知識を強調するインフォグラフィックを作成する必要があります。
それでは、リンク構築オペレーターを続けて、リソースページの機会を見つけましょう。
(11)。 ニッチ内のリソースページの機会を見つける
リソースページのリンク構築は、世の中で最も人気のあるリンク構築戦術の1つです。つまり、ニッチや業界に関係なく、リソースページを使用してリンクを構築することでビジネスにメリットをもたらすことができます。
しかし、リンク構築の機会のためのリソースページを見つける方法に入る前に、リソースページを簡単に定義しましょう。
リソースページは、役立つ業界リソースの厳選されたリストを含むWebページです。 たとえば、ケトダイエットに焦点を当てた食品ブログには、ケトレシピ、料理のヒント、ハウツーガイドなどに特化したWebページがある場合があります。
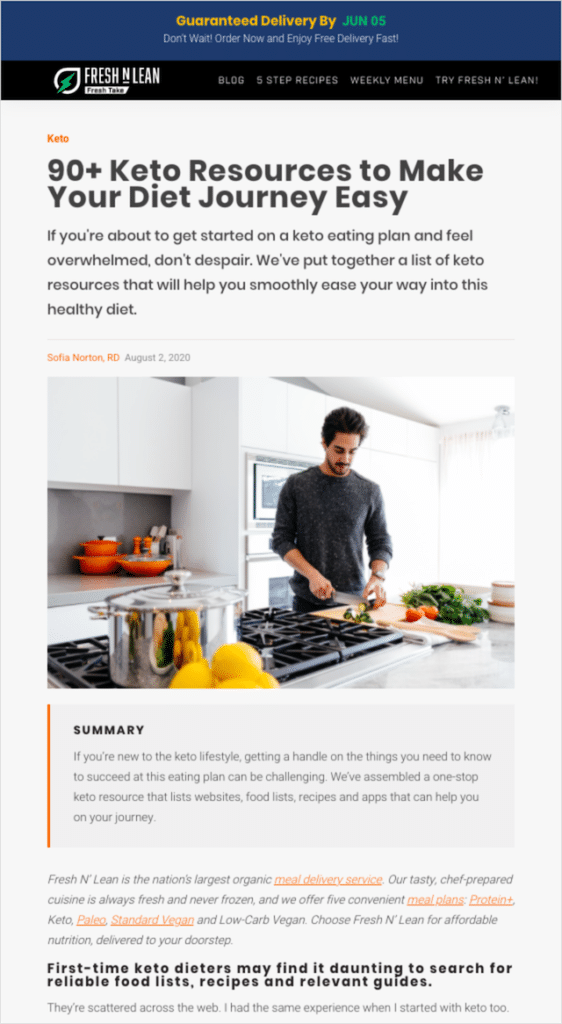
このようなページは、リソースページと見なされます。
リソースページは、多くの企業にとって頼りになるリンク構築戦略です(コンテンツの公開やゲストの投稿に次ぐ2番目)。
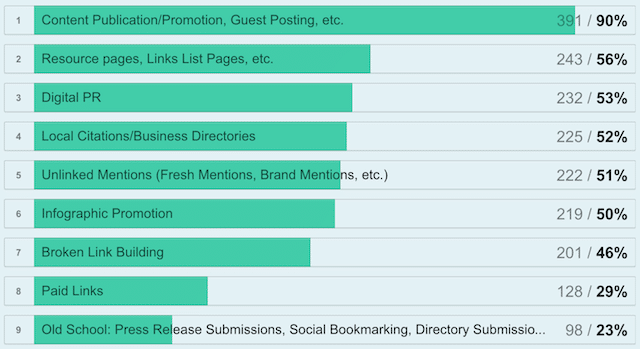
これは、リソースページが他のサイトの信頼できるコンテンツにリンクしており、通常は古くて信頼できるページ自体であるためです。
サイトの所有者は、リソースページのリンクの質と量を可能な限り高く保ちたいと考えています。 これは、関連するリソースがある場合(そしてそれが良い場合)、サイトの所有者はそれを含めるために多くの説得力を必要としないことを意味します。
では、検索演算子を使用してこれらのリソースページを検索し、リンクの構築を開始するにはどうすればよいでしょうか。
「intitle:」および「inurl」演算子を使用します。
intitle:” resources” inurl:” resources”[ニッチ/キーワード]
検索コマンド「allintitle:」を使用すると、検索をさらに絞り込んで、多くのジャンクを回避できます。
ニッチで機能するリソースページのリストを生成したら、その連絡先情報を見つけて連絡を取り、コンテンツをリソースとして提供する必要があります。
アウトリーチと言えば、検索オペレーターとの連絡先の詳細を見つける簡単な方法は次のとおりです。
(12)。 これらの検索オペレーターを使用してアウトリーチの見通しを改善する方法
上記の戦略のいずれかを使用してリンク構築の機会を見つけた場合は、コンテンツを売り込むことができるように、連絡する適切な人を見つける時が来ました。
正しい連絡先の詳細を見つけるのは難しい場合がありますが、検索演算子を使用して行うことができます。
site:targetdomain.com「作成者の名前」
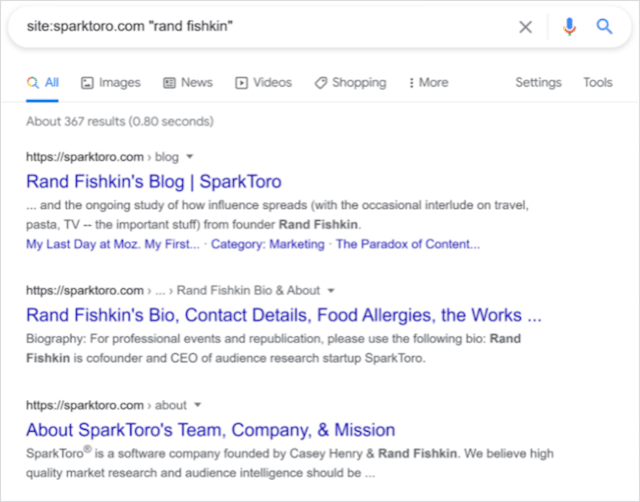
通常、著者のメールアドレスは著者の略歴または署名記事に記載されています。 しかし、彼らの電子メールアドレスがすぐに利用できない場合、あなたの将来の連絡先に連絡する別の方法はソーシャルメディアを介することです。
「site:」演算子を使用して、連絡先のソーシャルプロファイルを見つけることができます。
著者名targetsite.com(site:twitter.com OR site:facebook.com OR site:linkedin.com)
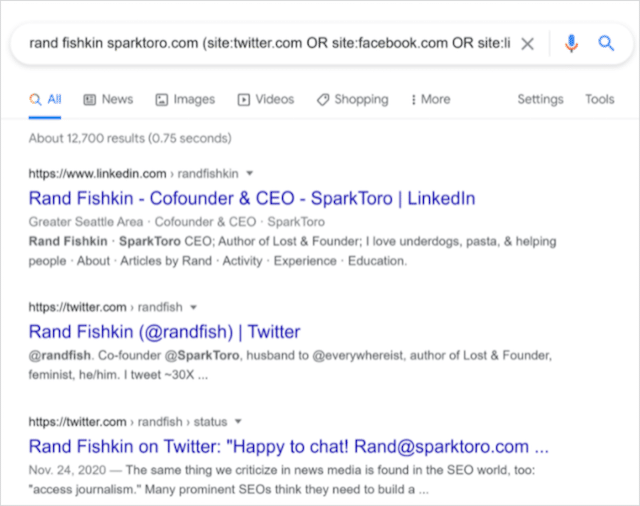
あなたが彼らのソーシャルメディアハンドルを手に入れたら、あなたは彼らのソーシャルアカウントを通して彼らに直接連絡することができます。 時々、何人かの著者は彼らの応答で彼らの電子メールアドレスにさえ言及するかもしれません。
それでもこれらの戦術でアウトリーチ活動に望ましい結果が得られない場合は、誰かの電子メールアドレスを見つけるための完全なガイドを確認できます。
(13)。 この検索演算子を使用して、競合他社のリンクを盗みます
リンクがないと、期間をランク付けできません。
そして、私の言葉だけを信じてはいけません。 グーグル自身は、リンクがそこにあるトップランクの要因の1つであることを認めています:
あなたの競争相手が検索結果であなたを上回っているなら、チャンスはそうです、彼らのバックリンクはあなたのものよりも優れています。
では、競合他社のリンクを盗んで自分のリンクに置き換えることができたらどうでしょうか。
あまりにも良さそうに聞こえますが、これは「link:」演算子を使用して可能です。
リンク:https://competitordomain.com -site:competitordomain.com
注: Googleは2017年に「link:」コマンドを正式に廃止しました。それでも、以下に示すように、リンク構築の取り組みに有益であることが証明される可能性のある結果が得られる可能性があります。
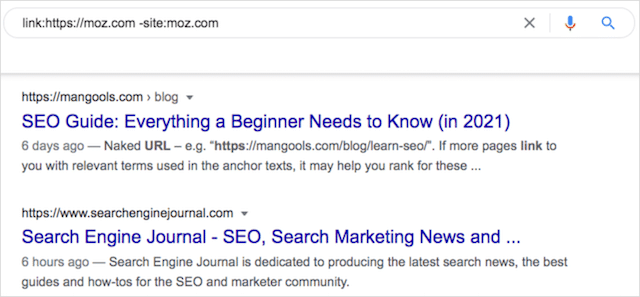
例からわかるように、「link:」コマンドを使用すると、競合他社を参照するサイトを検索できますが、排他的な「site:」演算子を使用すると、検索結果から競合他社のドメインが削除されます。
「link:」演算子は信頼性が低いため、競合他社からどのような種類の被リンクを取得できるかを試してみることをお勧めします。
ちなみに、競合他社をさらにスパイするために使用できる別の検索演算子があります。
(14)。 検索演算子を使用して競合他社のメンションを検索する方法
競合他社がウェブ上のどこで言及されているかを知ることは、マーケティング戦略を知らせるための優れた方法です。
あなたが彼らの言及リストをスワイプしてあなた自身のためにそれを使うことができればさらに良いです。
競合他社の言及の完全なリストを見つけるには、「intext:」演算子と排他的な「site:」コマンドを組み合わせて使用します。 外観は次のとおりです。
intext:” competor” -site:competitordomain.com
次のように、OR演算子を含めて、同時に複数の競合他社を検索することもできます。
(インテキスト:「競合他社1」またはインテキスト:「競合他社2」)-site:competitorone.com -site:competitortwo.com
競合他社の言及は、コンテンツの機会にも及びます。
たとえば、検索演算子を使用して、競合他社がコンテンツを作成したWebサイトを検索し、それらのサイトに自分でアプローチできます。
これらのサイトを見つけるには、引用符( "")演算子と除外またはマイナス(-)コマンドを使用します。
「作成者名は」-competitordomain.com
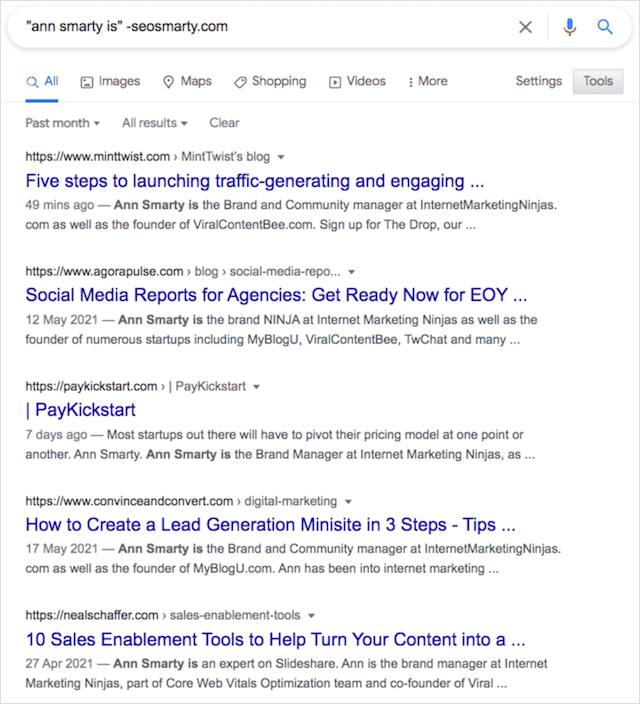
ゲスト投稿の機会と競合他社の言及を見つけるのに苦労したので、検索オペレーターの知識をコンテンツ作成の取り組みに適用しましょう。
(15)。 検索演算子を使用して、関連する統計でコンテンツを強化する方法
あなたのブログ投稿が研究に裏付けられた統計として彼らの読者から信頼を得るのを助けるものはほとんどありません。
影響力のある権威のあるウェブサイトからの説得力のある統計は、読者にあなたを信じさせ、あなたの投稿をより説得力のあるものにすることができます。
実際、統計の影響について書面で調査が行われ、研究者は、物語を1週間読んだ後、統計的証拠が逸話や物語の証拠よりも「説得力があり」、記憶に残ることを発見しました。
では、信頼できるサイトからコンテンツをサポートする統計をどのように見つけることができますか?
もちろん、あなたはグーグルに目を向けます!
「site:」演算子を使用すると、コンテンツの調査に裏付けられた統計を使用して信頼できるサイトを見つけることができます。
たとえば、色の科学とそれがマーケティングやブランディングに与える影響についてのブログ投稿を書いているとします。 利点や定義のリストだけでなく、実際の研究を見つけるには、キーワードを使用して科学サイトを検索します。
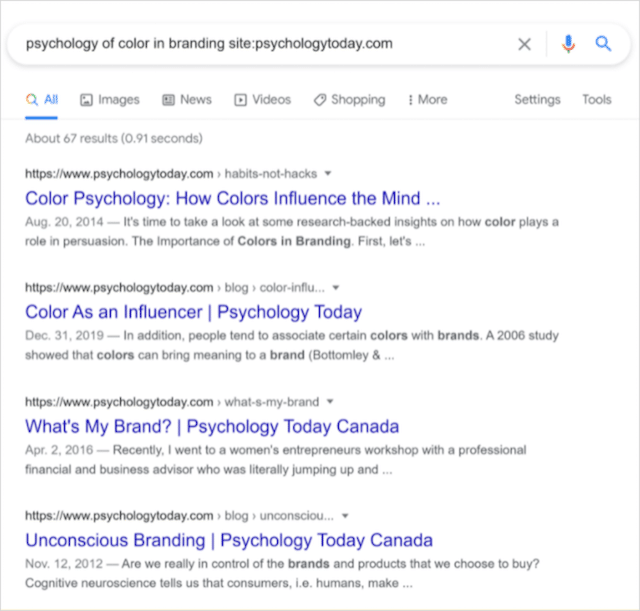
ORコマンドを追加して、同時に追加のソースを検索できます。
コンテンツを整理するときは、一部の統計がビジュアルとして最適に機能することを覚えておいてください。 結局のところ、私たちは視覚的な生き物であり、テキストデータよりもはるかに高速に視覚データを処理できます。 したがって、本当に読者の注意を引きたい場合は、ビジュアルを使用してください。
SEOのための執筆を改善するためのより多くの戦略とテクニックを学びたい場合は、SEOコンテンツフレームワークに関するこの記事をチェックしてください。
あなたに!
これらの検索オペレーターを習得すると、グーグルスキルを強力なSEOおよびマーケティングツールに変えることができます。 さまざまな検索演算子を組み合わせる方法を知っていると、以前はGoogleのSERPに隠されていた詳細情報を見つけるのに役立ちます。
もちろん、これらの演算子の有用性を理解するために、最も基本的なものからあいまいなものまで、これらすべての演算子を試してみることをお勧めします。
この投稿で言及されていない、グーグルを改善するのに役立つ素晴らしい組み合わせがある場合は、以下にコメントを残してください。
私はそれをこの検索演算子のデータベースに喜んで含めます。
さらに役立つように、SEOのリンク構築の機会をすばやく簡単に見つけるために使用できる検索オペレータージェネレーターを作成しました。
ターゲットキーワードをプラグインするだけで、私のジェネレーターは、コピーしてGoogleに貼り付けることができる数十の検索演算子を吐き出します。
今すぐツールにアクセスしてください(無料です)。
