
Şirket İçi Oracle Veritabanınızı AWS ile Senkronize Etme
Yayınlanan: 2023-01-11Yirmi yıldır kurumsal yazılım geliştirme sürecini en baştan izlersek, son birkaç yılın yadsınamaz eğiliminin veritabanlarını buluta taşıma olduğu açıktır.
Amacın mevcut şirket içi veritabanını Amazon Web Services (AWS) Bulut veritabanına getirmek olduğu birkaç geçiş projesine zaten dahil olmuştum. AWS dokümantasyon materyallerinden bunun ne kadar kolay olabileceğini öğreneceksiniz, ancak size böyle bir planın uygulanmasının her zaman kolay olmadığını ve başarısız olabileceği durumlar olduğunu söylemek için buradayım.

Bu gönderide, aşağıdaki durum için gerçek dünya deneyimini ele alacağım:
- Kaynak : Teorik olarak, kaynağınızın ne olduğu gerçekten önemli olmasa da (en popüler DB'lerin çoğu için çok benzer bir yaklaşım kullanabilirsiniz), Oracle uzun yıllar büyük kurumsal şirketlerde tercih edilen Veritabanı sistemiydi ve Odak noktam orası olacak.
- Hedef : Bu tarafta spesifik olmak için bir sebep yok. AWS'de herhangi bir hedef veritabanını seçebilirsiniz ve yaklaşım yine de uyacaktır.
- Mod : Tam yenileme veya artımlı yenileme yapabilirsiniz. Toplu veri yüklemesi (kaynak ve hedef durumları ertelenir) veya (yakın) gerçek zamanlı veri yüklemesi. Burada her ikisine de değinilecektir.
- Sıklık : Tek seferlik geçişin ardından buluta tam geçiş isteyebilirsiniz veya bir geçiş dönemi ve verilerin her iki tarafta da aynı anda güncel olmasını isteyebilirsiniz, bu da şirket içi ve AWS arasında günlük senkronizasyon geliştirme anlamına gelir. İlki daha basittir ve çok daha mantıklıdır, ancak ikincisi daha sık talep edilir ve çok daha fazla kırılma noktasına sahiptir. Burada ikisini de ele alacağım.
Sorun Açıklaması
Gereksinim genellikle basittir:
AWS içinde hizmetler geliştirmeye başlamak istiyoruz, bu nedenle lütfen tüm verilerimizi "ABC" veritabanına kopyalayın. Hızlı ve basit. Artık AWS içindeki verileri kullanmamız gerekiyor. Daha sonra, faaliyetlerimizle eşleştirmek için DB tasarımlarının hangi bölümlerinin değişeceğini bulacağız.
Daha ileri gitmeden önce dikkate alınması gereken bir şey var:
- "Sadece elimizde olanı kopyala ve sonra ilgilen" fikrine çok hızlı atlamayın. Demek istediğim, evet, yapabileceğiniz en kolay şey bu ve hızlı bir şekilde yapılacak, ancak bu, yeni bulut platformunun çoğunda ciddi bir yeniden düzenleme yapılmadan daha sonra düzeltilmesi imkansız olacak kadar temel bir mimari sorun yaratma potansiyeline sahip. . Bulut ekosisteminin şirket içi ekosistemden tamamen farklı olduğunu hayal edin. Zamanla birkaç yeni hizmet tanıtılacaktır. Doğal olarak, insanlar aynı şeyi çok farklı şekilde kullanmaya başlayacak. Şirket içi durumu bulutta 1:1 olarak çoğaltmak neredeyse hiçbir zaman iyi bir fikir değildir. Özel durumunuz olabilir, ancak bunu iki kez kontrol ettiğinizden emin olun.
- Gerekliliği aşağıdaki gibi bazı anlamlı şüphelerle sorgulayın:
- Yeni platformu kullanan tipik kullanıcı kim olacak? Şirket içindeyken işlemsel bir iş kullanıcısı olabilir; bulutta, bir veri bilimcisi veya veri ambarı analisti olabilir veya verinin ana kullanıcısı bir hizmet olabilir (örn. Databricks, Glue, makine öğrenimi modelleri vb.).
- Normal günlük işlerin buluta geçtikten sonra da devam etmesi bekleniyor mu? Değilse, nasıl değişmeleri bekleniyor?
- Zaman içinde önemli miktarda veri artışı planlıyor musunuz? Çoğu zaman buluta geçişin en önemli tek nedeni bu olduğundan, büyük olasılıkla yanıt evettir. Bunun için yeni bir veri modeli hazır olacaktır.
- Son kullanıcının, yeni veritabanının kullanıcılardan alacağı bazı genel, beklenen sorguları düşünmesini bekleyin. Bu, performansla ilgili kalmak için mevcut veri modelinin ne kadar değişeceğini tanımlayacaktır.
Taşımayı ayarlama
Hedef veritabanı seçildikten ve veri modeli tatmin edici bir şekilde tartışıldıktan sonra, bir sonraki adım AWS Schema Conversion Tool'u tanımaktır. Bu aracın hizmet edebileceği birkaç alan vardır:
- Kaynak veri modelini analiz edin ve ayıklayın. SCT, mevcut şirket içi veritabanında bulunanları okuyacak ve başlangıç için bir kaynak veri modeli oluşturacaktır.
- Hedef veritabanına dayalı olarak bir hedef veri modeli yapısı önerin.
- Hedef veri modelini yüklemek için hedef veritabanı dağıtım betikleri oluşturun (aracın kaynak veritabanından bulduklarına göre). Bu, dağıtım betikleri oluşturacak ve yürütüldükten sonra buluttaki veritabanı, şirket içi veritabanından veri yüklemeleri için hazır olacaktır.

Şimdi Şema Dönüştürme Aracını kullanmak için birkaç ipucu var.
İlk olarak, çıktıyı doğrudan kullanmak neredeyse hiçbir zaman söz konusu olmamalıdır. Verileri anlayışınıza ve amacınıza ve verilerin bulutta nasıl kullanılacağına bağlı olarak ayarlarınızı yapacağınız yerden daha çok referans sonuçları olarak düşünürdüm.
İkincisi, daha önce, tablolar muhtemelen bazı somut veri alanı varlıkları hakkında hızlı kısa sonuçlar bekleyen kullanıcılar tarafından seçilmişti. Ancak şimdi, veriler analitik amaçlar için seçilebilir. Örneğin, daha önce şirket içi veritabanında çalışan veritabanı dizinleri artık işe yaramaz olacak ve bu yeni kullanımla ilgili DB sisteminin performansını kesinlikle iyileştirmeyecektir. Benzer şekilde, verileri daha önce kaynak sistemde olduğu gibi hedef sistemde farklı şekilde bölümlemek isteyebilirsiniz.
Ayrıca, geçiş işlemi sırasında bazı veri dönüşümleri yapmayı düşünmek iyi olabilir; bu, temel olarak bazı tablolar için hedef veri modelini değiştirmek anlamına gelir (böylece artık 1:1 kopya olmazlar). Daha sonra, dönüştürme kurallarının geçiş aracına uygulanması gerekecektir.
Geçiş aracını yapılandırma
Kaynak ve hedef veritabanları aynı türdeyse (örneğin, AWS'de Oracle'a karşı şirket içi Oracle, PostgreSQL'e karşı Aurora Postgresql, vb.), o zaman somut veritabanının yerel olarak desteklediği özel bir geçiş aracı kullanmak en iyisidir ( örneğin, veri pompası dışa ve içe aktarmaları, Oracle Goldengate, vb.).
Ancak çoğu durumda kaynak ve hedef veritabanı uyumlu olmayacaktır ve bu durumda tercih edilen araç AWS Database Migration Service olacaktır.
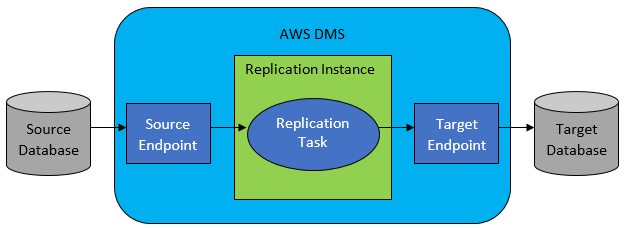
AWS DMS temel olarak tablo düzeyinde bir görev listesi yapılandırmanıza izin verir ve bu liste aşağıdakileri tanımlar:
- Bağlanmak için tam kaynak DB ve tablo nedir?
- Hedef tablo için verileri elde etmek için kullanılacak ifade belirtimleri.
- Kaynak verilerin hedef tablo verilerine (1:1 değilse) nasıl eşleneceğini tanımlayan dönüştürme araçları (varsa).
- Verilerin yükleneceği kesin hedef veritabanı ve tablo nedir?
DMS görevleri yapılandırması, JSON gibi kullanıcı dostu bir biçimde yapılır.
Şimdi en basit senaryoda yapmanız gereken tek şey, dağıtım komut dosyalarını hedef veritabanında çalıştırmak ve DMS görevini başlatmaktır. Ama bundan çok daha fazlası var.
Tek Seferlik Tam Veri Geçişi

Yürütülmesi en kolay durum, isteğin tüm veritabanını bir kez hedef bulut veritabanına taşımak olduğu zamandır. Ardından, temel olarak, yapılması gereken her şey aşağıdaki gibi görünecektir:

- Her kaynak tablo için DMS Görevi tanımlayın.
- DMS işlerinin yapılandırmasını doğru şekilde belirttiğinizden emin olun. Bu, makul paralelliğin ayarlanması, değişkenlerin önbelleğe alınması, DMS sunucu yapılandırması, DMS kümesinin boyutlandırılması vb. anlamına gelir. Bu, kapsamlı test ve optimum yapılandırma durumunun ince ayarını gerektirdiğinden genellikle en çok zaman alan aşamadır.
- Her hedef tablonun, hedef veritabanında beklenen tablo yapısında oluşturulduğundan (boş) emin olun.
- Veri geçişinin gerçekleştirileceği bir zaman aralığı planlayın. Bundan önce, geçişin tamamlanması için (performans testleri yaparak) zaman penceresinin yeterli olduğundan emin olun. Geçiş sırasında, kaynak veritabanı performans açısından kısıtlanabilir. Ayrıca, geçişin çalışacağı süre boyunca kaynak veritabanının değişmemesi beklenir. Aksi takdirde, geçiş yapıldıktan sonra taşınan veriler kaynak veritabanında saklananlardan farklı olabilir.
DMS konfigürasyonu iyi yapılırsa, bu senaryoda kötü bir şey olmaz. Her bir kaynak tablo alınacak ve AWS hedef veritabanına kopyalanacaktır. Tek kaygı, etkinliğin performansı ve yetersiz depolama alanı nedeniyle başarısız olmaması için her adımda boyutlandırmanın doğru olduğundan emin olmaktır.
Kademeli Günlük Senkronizasyon

İşlerin karmaşıklaşmaya başladığı yer burasıdır. Demek istediğim, eğer dünya ideal olsaydı, o zaman muhtemelen her zaman gayet iyi çalışırdı. Ama dünya asla ideal değildir.
DMS, iki modda çalışacak şekilde yapılandırılabilir:
- Tam yük – yukarıda açıklanan ve kullanılan varsayılan mod. DMS görevleri, siz onları başlattığınızda veya başlamaları planlandığında başlatılır. Bittiğinde, DMS görevleri yapılır.
- Veri Yakalamayı Değiştir (CDC) – bu modda, DMS görevi sürekli olarak çalışır. DMS, tablo seviyesindeki bir değişiklik için kaynak veritabanını tarar. Değişiklik olursa, değiştirilen tabloyla ilgili DMS görevi içindeki yapılandırmaya dayalı olarak değişikliği hemen hedef veritabanında çoğaltmaya çalışır.
CDC'ye giderken, başka bir seçim yapmanız gerekir - yani, CDC'nin delta değişikliklerini kaynak DB'den nasıl çıkaracağı.
1 numara. Oracle Redo Logs Okuyucu
Seçeneklerden biri, CDC'nin değişen verileri almak için kullanabileceği ve en son değişikliklere bağlı olarak aynı değişiklikleri hedef veritabanında çoğaltabileceği Oracle'dan yerel veritabanı redo logs okuyucusunu seçmektir.
Kaynak olarak Oracle ile uğraşıyorsanız bu bariz bir seçim gibi görünse de, bir sorun var: Oracle redo logs okuyucu, kaynak Oracle kümesini kullanır ve bu nedenle veritabanında çalışan diğer tüm etkinlikleri doğrudan etkiler (aslında doğrudan etkin oturumlar oluşturur. veritabanı).
Ne kadar çok DMS Görevi yapılandırırsanız (veya paralel olarak ne kadar çok DMS kümesi), muhtemelen Oracle kümesini o kadar çok büyütmeniz gerekir; temel olarak, birincil Oracle veritabanı kümenizin dikey ölçeklemesini ayarlayın. Bu, günlük senkronizasyon projede uzun bir süre kalmak üzereyse, çözümün toplam maliyetlerini kesinlikle etkileyecektir.
2 numara. AWS DMS Günlük Madenci
Yukarıdaki seçeneğin aksine bu, aynı sorun için yerel bir AWS çözümüdür. Bu durumda DMS, kaynak Oracle DB'yi etkilemez. Bunun yerine, Oracle redo günlüklerini DMS kümesine kopyalar ve tüm işlemleri orada yapar. Oracle kaynaklarını korurken, daha fazla operasyon söz konusu olduğundan daha yavaş olan çözümdür. Ayrıca, kolayca tahmin edilebileceği gibi, Oracle redo günlükleri için özel okuyucu muhtemelen Oracle'ın yerel okuyucusu olarak işinde daha yavaştır.
Kaynak veritabanının boyutuna ve oradaki günlük değişikliklerin sayısına bağlı olarak, en iyi senaryoda, şirket içi Oracle veritabanındaki verilerin AWS bulut veritabanına neredeyse gerçek zamanlı artımlı senkronizasyonuyla sonuçlanabilirsiniz.
Diğer senaryolarda, yine de gerçek zamanlı senkronizasyona yakın olmayacak, ancak kaynak ve hedef küme performans yapılandırmasını ve paralelliği ayarlayarak veya bunlarla deneyler yaparak kabul edilen gecikmeye (kaynak ve hedef arasında) mümkün olduğunca yaklaşmaya çalışabilirsiniz. DMS görevlerinin miktarı ve bunların CDC örnekleri arasında dağıtılması.
Ayrıca hangi kaynak tablo değişikliklerinin CDC tarafından desteklendiğini (örneğin bir sütun eklenmesi gibi) öğrenmek isteyebilirsiniz çünkü tüm olası değişiklikler desteklenmez. Bazı durumlarda, tek yol hedef tabloyu manuel olarak değiştirmek ve CDC görevini sıfırdan yeniden başlatmaktır (yol boyunca hedef veritabanındaki tüm mevcut verileri kaybeder).
İşler Ters Gittiğinde, Ne Olursa Olsun

Bunu zor yoldan öğrendim, ancak günlük çoğaltma vaadinin elde edilmesinin zor olduğu, DMS ile bağlantılı belirli bir senaryo var.
DMS, yineleme günlüklerini yalnızca belirli bir hızda işleyebilir. Görevlerinizi yürüten daha fazla DMS örneği olup olmaması önemli değildir. Yine de her bir DMS örneği, yineleme günlüklerini yalnızca tanımlanmış tek bir hızla okur ve her birinin bunların tamamını okuması gerekir. Oracle redo logs veya AWS log miner kullanmanız fark etmez. Her ikisinin de bu sınırı var.
Kaynak veritabanı, bir gün içinde çok sayıda değişiklik içeriyorsa, Oracle yineleme günlükleri her gün gerçekten çılgınca büyüyorsa (500GB + büyük gibi), CDC işe yaramayacak. Çoğaltma gün sonundan önce tamamlanmayacaktır. İşlenmemiş bazı işleri ertesi güne getirecek ve burada kopyalanacak yeni bir dizi değişiklik zaten bekliyor. İşlenmemiş veri miktarı yalnızca günden güne artacaktır.
Bu özel durumda, CDC bir seçenek değildi (birçok performans testi ve gerçekleştirdiğimiz denemeden sonra). Geçerli günden en azından tüm delta değişikliklerinin aynı gün çoğaltılmasını sağlamanın tek yolu, ona şu şekilde yaklaşmaktı:
- Çok sık kullanılmayan gerçekten büyük masaları ayırın ve bunları yalnızca haftada bir kez çoğaltın (örneğin, hafta sonları).
- Çok büyük olmayan ama yine de büyük olan tabloların çoğaltmasını birkaç DMS görevi arasında bölünecek şekilde yapılandırın; bir tablo sonunda paralel olarak 10 veya daha fazla ayrılmış DMS görevi tarafından geçirildi, bu da DMS görevleri arasındaki veri bölünmesinin farklı olmasını (burada özel kodlama söz konusu) ve bunları günlük olarak yürütmesini sağlıyor.
- Daha fazla (bu durumda 4 adede kadar) BYS örneği ekleyin ve BYS görevlerini bunlar arasında eşit olarak bölün; bu, yalnızca tablo sayısına göre değil aynı zamanda boyuta göre de anlamına gelir.
Temel olarak, günlük verileri çoğaltmak için DMS'nin tam yük modunu kullandık çünkü bu, en azından aynı gün veri çoğaltmanın tamamlanmasını sağlamanın tek yoluydu.
Mükemmel bir çözüm değil ama hala orada ve yıllar sonra bile hala aynı şekilde çalışıyor. Yani, belki de o kadar da kötü bir çözüm değil.