
データ変換のクイックガイド
公開: 2022-11-09大規模なデータセットを整理、マージ、標準化、およびフォーマットして、ビジネス インテリジェンスを抽出したいとお考えですか? ETL プロセスにおけるデータ変換に関するこの究極のガイドをお読みください。
企業は、ビジネス インテリジェンス (BI) ツールが利用できる形式でデータを取得することはほとんどありません。 通常、データ コネクタとリポジトリは、未加工の整理されていないデータで攻撃します。 このような生データからパターンを抽出することはできません。
ビジネス ニーズに合わせてデータを構造化するには、データ変換などの特殊なプロセスが必要です。 また、不正確なデータセットが目に見えないビジネス チャンスも明らかにします。
この記事では、データ変換について基礎から説明します。 読んだ後、このテーマに関する専門的な知識を身につけ、データ変換プロジェクトをうまく計画して実行できるようになります。
データ変換とは
基本的に、データ変換は、データの本質と内容をそのまま維持し、その外観を変更するデータ処理の技術的なステップです。 ほとんどの場合、データ サイエンティストは次のパラメーターで変更を行います。
- データ構造
- データ形式
- 標準化
- 組織
- マージ
- クレンジング
その結果、整理された形式のクリーンなデータが得られます。 最終的な形式と構造は、ビジネスで使用する BI ツールによって異なります。 また、会計、財務、在庫、販売などのさまざまなビジネス セクションでは、入力データの構造が異なるため、書式設定は部門ごとに異なる場合があります。
このデータ変更中に、データ サイエンティストはビジネス ルールもデータに適用します。 これらのルールは、ビジネス アナリストが処理されたデータからパターンを抽出し、リーダーシップ チームが情報に基づいた意思決定を行うのに役立ちます。
さらに、データ変換は、さまざまなデータ モデルを 1 つの集中型データベースにマージできるフェーズです。 製品、サービス、販売プロセス、マーケティング方法、在庫、会社の支出などを比較するのに役立ちます。
データ変換の種類
#1。 データクリーニング
このプロセスを通じて、人々は不正確、不正確、無関係、または不完全なデータ セットまたはそのコンポーネントを特定します。 その後、データを変更、置換、または削除して、精度を高めることができます。 結果のデータを使用して意味のある洞察を生成できるように、慎重な分析に依存しています。
#2。 データ重複除去
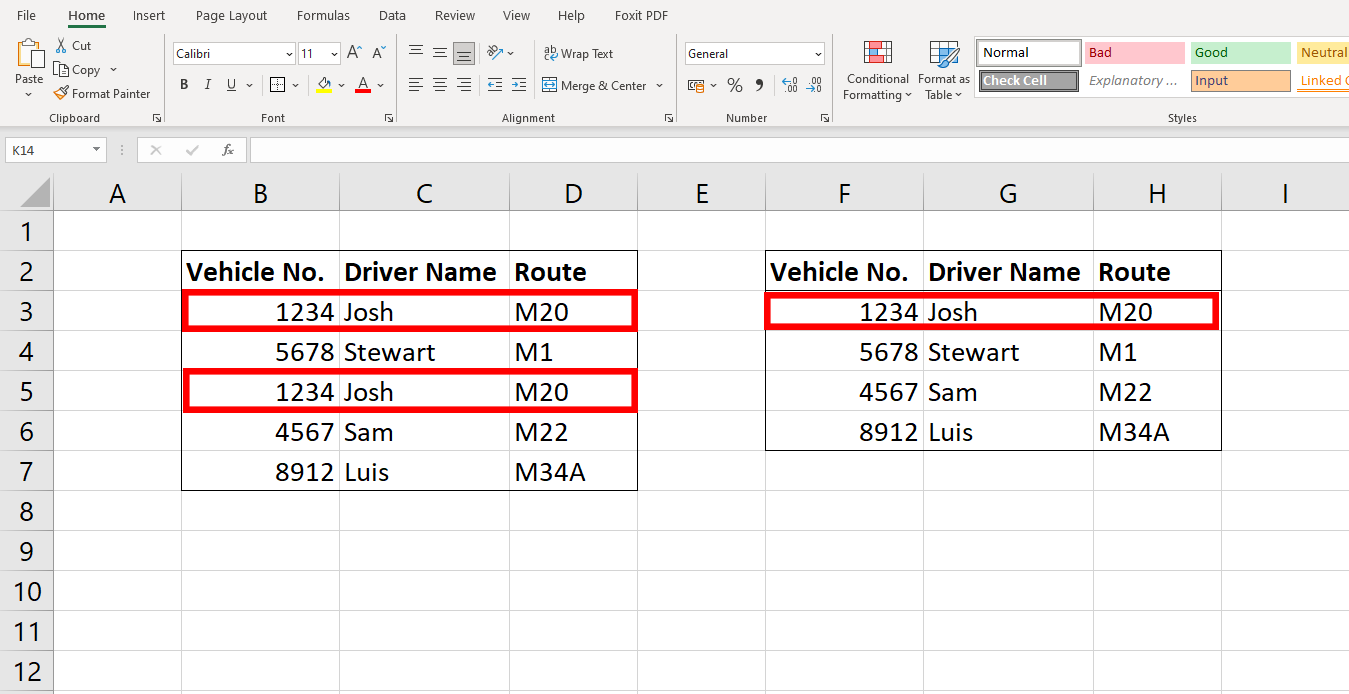
重複したデータ入力は、データ マイニング プロセスで混乱や誤算を引き起こす可能性があります。 データ重複除去を使用すると、データセットのすべての冗長エントリが抽出されるため、データセットは自由に複製できます。
このプロセスにより、企業が重複データを保存および処理するために必要だった可能性のある費用を節約できます。 また、そのようなデータがパフォーマンスに影響を与えたり、クエリ処理を遅くしたりするのを防ぎます。
#3。 データ集約
集約とは、データを収集、検索、および簡潔な形式で提示することを指します。 企業は、このタイプのデータ変換を実行して、複数のデータ ソースから収集し、それらを 1 つに結合してデータ分析を行う場合があります。
このプロセスは、製品、運用、マーケティング、および価格設定に関する戦略的決定を行う際に非常に役立ちます。
#4。 データ統合
名前が示すように、このタイプのデータ変換は、さまざまなソースからのデータを統合します。
さまざまな部門に関連するデータを結合し、統一されたビューを提供するため、企業の誰もがデータにアクセスして、ML テクノロジーとビジネス インテリジェンス分析に使用できます。
さらに、データ管理プロセスの主要な要素と見なされます。
#5。 データフィルタリング
今日、企業は膨大な量のデータを処理する必要があります。 ただし、すべてのプロセスですべてのデータが必要なわけではありません。 このため、企業はデータセットをフィルタリングして、洗練されたデータを取得する必要があります。
フィルタリングにより、無関係なデータ、重複するデータ、または機密データを排除し、必要なものを分離します。 このプロセスにより、企業はデータ エラーを最小限に抑え、正確なレポートとクエリ結果を生成できます。
#6。 データ要約
これは、生成されたデータの包括的な要約を提示することを意味します。 どのようなプロセスでも、生データはまったく適していません。 エラーが含まれている可能性があり、特定のアプリケーションが理解できない形式で使用できる場合があります。
これらの理由から、企業はデータ要約を実行して生データの要約を生成します。 したがって、要約されたバージョンからデータの傾向とパターンにアクセスしやすくなります。
#7。 データ分割
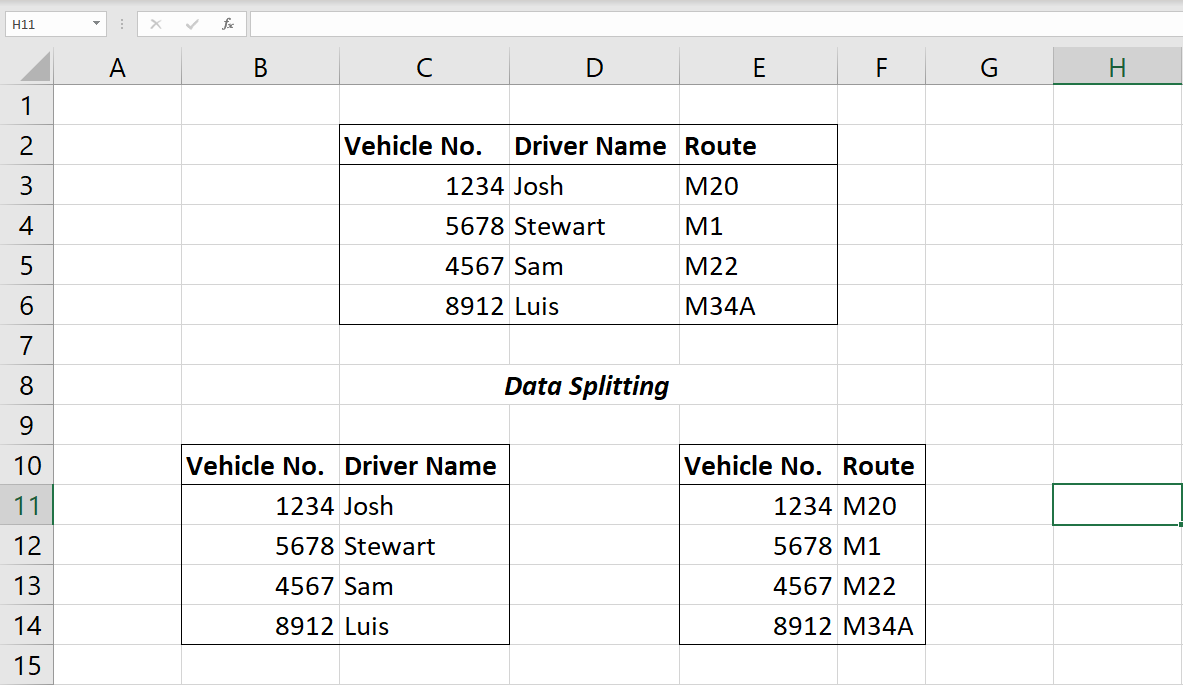
このプロセスでは、データ セットのエントリがさまざまなセグメントに分割されます。 データ分割の主な目的は、相互検証のためにデータセットを開発、トレーニング、およびテストすることです。
さらに、このプロセスにより、ミッションクリティカルで機密性の高いデータを不正アクセスから保護できます。 分割することで、企業は機密データを暗号化し、別のサーバーに保存できます。
#8。 データ検証
すでに持っているデータを検証することも、一種のデータ変換です。 このプロセスには、データの正確性、品質、完全性をクロスチェックすることが含まれます。 データセットをさらに処理するために使用する前に、後の段階での問題を回避するためにデータセットを検証することが不可欠です。
データ変換の実行方法
方法の選択
ビジネス ニーズに応じて、次のデータ変換方法のいずれかを使用できます。
#1。 オンサイト ETL ツール
膨大なデータセットを定期的に処理する必要があり、特注の変換プロセスも必要な場合は、オンサイトの ETL ツールを利用できます。 これらは堅牢なワークステーションで実行され、より大きなデータ セットをすばやく処理できます。 ただし、所有コストが高すぎます。
#2。 クラウドベースの ETL Web アプリ
小規模、中規模、および新興企業は、手頃な価格であるため、主にクラウドベースのデータ変換アプリに依存しています。 このようなアプリは、週または月に 1 回データを準備する場合に適しています。
#3。 変換スクリプト
比較的小規模なデータセットで小規模なプロジェクトに取り組んでいる場合は、Python、Excel、SQL、VBA、マクロなどのレガシー システムをデータ変換に使用することをお勧めします。
データセットを変換する手法の選択
どの方法を選択するかがわかったので、次に適用する手法を検討する必要があります。 生データと探している最終的なパターンに応じて、以下からいくつかまたはすべてを選択できます。
#1。 データの統合
ここでは、さまざまなソースからの 1 つの要素のデータを統合し、要約されたテーブルを形成します。 たとえば、アカウント、請求書、販売、マーケティング、ソーシャル メディア、競合他社、ウェブサイト、ビデオ共有プラットフォームなどから顧客データを蓄積し、表形式のデータベースを形成します。
#2。 データの並べ替えとフィルタリング
生のフィルター処理されていないデータを BI アプリに送信しても、時間とお金が無駄になるだけです。 代わりに、不要なデータや無関係なデータをデータセットから除外し、分析可能なコンテンツを含むデータのチャンクのみを送信する必要があります。
#3。 データのスクラビング

また、データ サイエンティストは生データをスクラブして、ノイズ、破損したデータ、無関係なコンテンツ、誤ったデータ、タイプミスなどを取り除きます。
#4。 データセットの離散化
特に連続データの場合、離散化手法を使用して、連続フローを変更せずにデータの大きなチャンク間に間隔を追加する必要があります。 連続したデータセットに分類された有限の構造を与えると、トレンドを描画したり、長期的な平均を計算したりすることが容易になります。
#5。 データの一般化
これは、データ プライバシー規制に準拠するために、個人に適したデータセットを非個人的で一般的なデータに変換する手法です。 さらに、このプロセスでは、大規模なデータセットを簡単に分析可能な形式に変換することもできます。
#6。 重複の削除
重複があると、データ ウェアハウジング料金としてより多くの支払いを余儀なくされ、最終的なパターンや洞察が歪められる可能性があります。 したがって、チームはデータセット全体を綿密にスキャンして重複やコピーなどを探し、変換されたデータベースからそれらを除外する必要があります。
#7。 新しい属性の作成
この段階で、新しいフィールド、列ヘッダー、または属性を導入して、データをより整理することができます。
#8。 標準化と正規化
ここで、好みのデータベース構造、使用法、およびデータ視覚化モデルに応じて、データセットを正規化および標準化する必要があります。 標準化により、組織のすべての部門で同じデータセットを使用できるようになります。
#9。 データの平滑化
平滑化とは、大規模なデータセットから無意味で歪んだデータを削除することです。 また、データをスキャンして、分析チームが期待するパターンから逸脱する可能性のある不均衡な変更を探します。

変換されたデータセットへの手順
#1。 データの発見

このステップでは、データセットとそのモデルを理解し、必要な変更を決定します。 データ プロファイリング ツールを使用して、データベース、ファイル、スプレッドシートなどをこっそり見ることができます。
#2。 データ変換マッピング
このフェーズでは、変換プロセスに関する多くのことを決定します。これらは次のとおりです。
- レビュー、編集、書式設定、クレンジング、および変更が必要な要素
- そのような変化の背後にある理由は何ですか
- これらの変更を実現する方法
#3。 コードの生成と実行
データ サイエンティストは、データ変換コードを記述して、プロセスを自動的に実行します。 Python、SQL、VBA、PowerShell などを使用できます。ノーコード ツールを使用する場合は、生データをそのツールにアップロードし、必要な変更を示す必要があります。
#4。 レビューとロード
ここで、出力ファイルを確認し、適切な変更があるかどうかを確認する必要があります。 次に、データセットを BI アプリにロードできます。
データ変換の利点
#1。 より良いデータ編成
データ変換とは、データを変更して分類し、個別に保管して簡単に見つけられるようにすることです。 そのため、人間とアプリケーションの両方が、変換されたデータをより適切に整理して簡単に使用できます。
#2。 データ品質の向上
このプロセスにより、データ品質の問題を排除し、不良データに伴うリスクを軽減することもできます。 これで、誤解、矛盾、データの欠落の可能性が少なくなりました。 企業は成功を収めるために正確な情報を必要とするため、重要な意思決定を行うには変革が不可欠です。
#3。 より簡単なデータ管理

データ変換により、チームのデータ管理プロセスも簡素化されます。 多数のソースからの増大する量のデータを扱う組織では、このプロセスが必要です。
#4。 幅広い用途
データ変換の最大のメリットの 1 つは、企業がデータを最大限に活用できることです。 このプロセスでは、データを標準化し、より使いやすくします。 その結果、企業は同じデータセットをより多くの目的に使用できます。
さらに、より多くのアプリケーションが変換されたデータを使用できます。これは、これらのアプリケーションにはデータのフォーマットに関する固有の要件があるためです。
#5。 計算上の課題が少ない
整理されていないデータは、不適切なインデックス作成、null 値、エントリの重複などにつながる可能性があります。変換することで、企業はデータを標準化し、アプリケーションがデータ処理中に発生する計算エラーの可能性を減らすことができます。
#6。 クエリの高速化
データ変換とは、データを並べ替えて、整理された方法でウェアハウスに格納することです。 これにより、クエリが高速になり、BI ツールの使用が最適化されます。
#7。 リスクの軽減
不正確、不完全、および一貫性のないデータを使用すると、意思決定と分析が妨げられます。 データが変換されると、標準化されます。 したがって、高品質のデータは、不正確な計画による金銭的および評判の損失に直面する可能性を減らします。
#8。 洗練されたメタデータ
企業はますます多くのデータを処理する必要があるため、データ管理が課題になります。 データ変換により、メタデータの混乱を回避できます。 これで、データの管理、並べ替え、検索、および使用に役立つ洗練されたメタデータを取得できます。
ツール
DBT

DBT は、データ変換のワークフローです。 また、データ分析コードを一元化し、モジュール化するのにも役立ちます。 言うまでもなく、データセットのバージョン管理、変換されたデータの共同作業、データ モデルのテスト、クエリの文書化など、データ管理用の他のツールも利用できます。
Qlik

Qlik は、大量のデータをソースから BI アプリ、ML プロジェクト、データ ウェアハウスなどの宛先に転送する際の複雑さ、コスト、時間を最小限に抑えます。 自動化とアジャイルな方法論を使用して、ETL コードの多忙な手動コーディングなしでデータを変換します。
どーも

Domo は、SQL データベース変換用のドラッグ アンド ドロップ インターフェースを提供し、データ マージを簡単かつ自動的に行います。 さらに、このツールを使用すると、さまざまなチームが同じデータセットを競合することなく分析できるように、データを簡単に利用できるようになります。
イージーモーフ

EasyMorph は、Excel、VBA、SQL、Python などのレガシー システムを使用した骨の折れるデータ変換プロセスから解放されます。 これは、データ サイエンティスト、データ アナリスト、および財務アナリストに、データを変換し、可能な場合は自動化するためのビジュアル ツールを提供します。
最後の言葉
データ変換は、さまざまなビジネス セクションの同じデータ セットから卓越した価値を引き出すことができる重要なプロセスです。 これは、オンサイト BI アプリの ETL やクラウドベースのデータ ウェアハウスとデータ レイクの ELT などのデータ処理方法の標準フェーズでもあります。
データの変換後に得られる高品質で標準化されたデータは、マーケティング、販売、製品開発、価格調整、新しいユニットなどのビジネス プランを設定する際に重要な役割を果たします。
次に、データ サイエンス / ML プロジェクトのオープン データセットを確認できます。