
Detección de anomalías: guía para prevenir intrusiones en la red
Publicado: 2023-01-09Los datos son una parte indispensable de las empresas y organizaciones, y solo son valiosos cuando se estructuran correctamente y se administran de manera eficiente.
Según una estadística, el 95 % de las empresas hoy en día consideran que la gestión y estructuración de datos no estructurados es un problema.
Aquí es donde entra en juego la minería de datos. Es el proceso de descubrir, analizar y extraer patrones significativos e información valiosa de grandes conjuntos de datos no estructurados.
Las empresas utilizan software para identificar patrones en grandes lotes de datos para obtener más información sobre sus clientes y el público objetivo y desarrollar estrategias comerciales y de marketing para mejorar las ventas y reducir los costos.
Además de este beneficio, la detección de fraudes y anomalías son las aplicaciones más importantes de la minería de datos.
Este artículo explica la detección de anomalías y explora más a fondo cómo puede ayudar a prevenir filtraciones de datos e intrusiones en la red para garantizar la seguridad de los datos.
¿Qué es la detección de anomalías y sus tipos?

Si bien la minería de datos implica encontrar patrones, correlaciones y tendencias que se vinculan entre sí, es una excelente manera de encontrar anomalías o puntos de datos atípicos dentro de la red.
Las anomalías en la minería de datos son puntos de datos que difieren de otros puntos de datos en el conjunto de datos y se desvían del patrón de comportamiento normal del conjunto de datos.
Las anomalías se pueden clasificar en distintos tipos y categorías, que incluyen:
- Cambios en los eventos: se refieren a cambios repentinos o sistemáticos del comportamiento normal anterior.
- Valores atípicos: pequeños patrones anómalos que aparecen de forma no sistemática en la recopilación de datos. Estos se pueden clasificar en valores atípicos globales, contextuales y colectivos.
- Derivas: cambio gradual, unidireccional y a largo plazo en el conjunto de datos.
Por lo tanto, la detección de anomalías es una técnica de procesamiento de datos muy útil para detectar transacciones fraudulentas, manejar estudios de casos con desequilibrio de clase alta y detección de enfermedades para construir modelos sólidos de ciencia de datos.
Por ejemplo, una empresa puede querer analizar su flujo de efectivo para encontrar transacciones anormales o recurrentes en una cuenta bancaria desconocida para detectar fraudes y realizar una investigación adicional.
Beneficios de la detección de anomalías
La detección de anomalías en el comportamiento del usuario ayuda a fortalecer los sistemas de seguridad y los hace más precisos y precisos.
Analiza y da sentido a la variada información que proporcionan los sistemas de seguridad para identificar amenazas y riesgos potenciales dentro de la red.
Estas son las ventajas de la detección de anomalías para las empresas:
- Detección en tiempo real de amenazas de ciberseguridad y violaciones de datos , ya que sus algoritmos de inteligencia artificial (IA) escanean constantemente sus datos para encontrar comportamientos inusuales.
- Hace que el seguimiento de actividades y patrones anómalos sea más rápido y fácil que la detección manual de anomalías, lo que reduce el trabajo y el tiempo necesarios para resolver las amenazas.
- Minimiza los riesgos operativos mediante la identificación de errores operativos, como caídas repentinas del rendimiento, incluso antes de que ocurran.
- Ayuda a eliminar los principales daños comerciales mediante la detección rápida de anomalías, ya que sin un sistema de detección de anomalías, las empresas pueden tardar semanas y meses en identificar amenazas potenciales.
Por lo tanto, la detección de anomalías es un gran activo para las empresas que almacenan grandes conjuntos de datos comerciales y de clientes para encontrar oportunidades de crecimiento y eliminar las amenazas de seguridad y los cuellos de botella operativos.
Técnicas de Detección de Anomalías
La detección de anomalías utiliza varios procedimientos y algoritmos de aprendizaje automático (ML) para monitorear datos y detectar amenazas.
Estas son las principales técnicas de detección de anomalías:
#1. Técnicas de aprendizaje automático

Las técnicas de Machine Learning utilizan algoritmos de ML para analizar datos y detectar anomalías. Los diferentes tipos de algoritmos de aprendizaje automático para la detección de anomalías incluyen:
- Algoritmos de agrupamiento
- Algoritmos de clasificación
- Algoritmos de aprendizaje profundo
Y las técnicas de ML comúnmente utilizadas para la detección de anomalías y amenazas incluyen máquinas de vectores de soporte (SVM), agrupación en clústeres de k-means y codificadores automáticos.
#2. Técnicas Estadísticas
Las técnicas estadísticas usan modelos estadísticos para detectar patrones inusuales (como fluctuaciones inusuales en el rendimiento de una máquina en particular) en los datos para detectar valores que se encuentran más allá del rango de los valores esperados.
Las técnicas comunes de detección de anomalías estadísticas incluyen pruebas de hipótesis, IQR, puntaje Z, puntaje Z modificado, estimación de densidad, diagrama de caja, análisis de valor extremo e histograma.
#3. Técnicas de Minería de Datos

Las técnicas de minería de datos utilizan técnicas de clasificación y agrupación de datos para encontrar anomalías dentro del conjunto de datos. Algunas técnicas comunes de anomalías de minería de datos incluyen el agrupamiento espectral, el agrupamiento basado en la densidad y el análisis de componentes principales.
Los algoritmos de minería de datos de agrupamiento se utilizan para agrupar diferentes puntos de datos en grupos en función de su similitud para encontrar puntos de datos y anomalías que se encuentran fuera de estos grupos.
Por otro lado, los algoritmos de clasificación asignan puntos de datos a clases predefinidas específicas y detectan puntos de datos que no pertenecen a estas clases.
#4. Técnicas basadas en reglas
Como sugiere el nombre, las técnicas de detección de anomalías basadas en reglas utilizan un conjunto de reglas predeterminadas para encontrar anomalías en los datos.
Estas técnicas son comparativamente más fáciles y simples de configurar, pero pueden ser inflexibles y pueden no ser eficientes para adaptarse al comportamiento y los patrones cambiantes de los datos.
Por ejemplo, puede programar fácilmente un sistema basado en reglas para marcar las transacciones que excedan un monto específico en dólares como fraudulentas.
#5. Técnicas específicas de dominio
Puede utilizar técnicas específicas de dominio para detectar anomalías en sistemas de datos específicos. Sin embargo, si bien pueden ser muy eficientes para detectar anomalías en dominios específicos, pueden ser menos eficientes en otros dominios fuera del especificado.
Por ejemplo, utilizando técnicas específicas de dominio, puede diseñar técnicas específicamente para encontrar anomalías en las transacciones financieras. Pero es posible que no funcionen para encontrar anomalías o caídas de rendimiento en una máquina.
Necesidad de aprendizaje automático para la detección de anomalías
El aprendizaje automático es muy importante y muy útil en la detección de anomalías.
Hoy en día, la mayoría de las empresas y organizaciones que requieren detección de valores atípicos manejan grandes cantidades de datos, desde texto, información de clientes y transacciones hasta archivos multimedia como imágenes y contenido de video.
Pasar por todas las transacciones bancarias y los datos generados cada segundo manualmente para generar información significativa es casi imposible. Además, la mayoría de las empresas enfrentan desafíos y grandes dificultades para estructurar datos no estructurados y organizar los datos de manera significativa para el análisis de datos.
Aquí es donde las herramientas y técnicas como el aprendizaje automático (ML) juegan un papel muy importante en la recopilación, limpieza, estructuración, organización, análisis y almacenamiento de grandes volúmenes de datos no estructurados.
Las técnicas y algoritmos de aprendizaje automático procesan grandes conjuntos de datos y brindan la flexibilidad para usar y combinar diferentes técnicas y algoritmos para brindar los mejores resultados.
Además, el aprendizaje automático también ayuda a agilizar los procesos de detección de anomalías para aplicaciones del mundo real y ahorra recursos valiosos.
Aquí hay algunos beneficios más y la importancia del aprendizaje automático en la detección de anomalías:
- Facilita la detección de anomalías de escala al automatizar la identificación de patrones y anomalías sin necesidad de una programación explícita.
- Los algoritmos de Machine Learning son altamente adaptables a patrones cambiantes de conjuntos de datos, lo que los hace altamente eficientes y robustos con el tiempo.
- Maneja fácilmente conjuntos de datos grandes y complejos, lo que hace que la detección de anomalías sea eficiente a pesar de la complejidad del conjunto de datos.
- Garantiza la identificación y detección temprana de anomalías al identificar las anomalías a medida que ocurren, ahorrando tiempo y recursos.
- Los sistemas de detección de anomalías basados en aprendizaje automático ayudan a lograr niveles más altos de precisión en la detección de anomalías en comparación con los métodos tradicionales.
Por lo tanto, la detección de anomalías junto con el aprendizaje automático ayuda a una detección más rápida y temprana de anomalías para evitar amenazas de seguridad e infracciones maliciosas.

Algoritmos de aprendizaje automático para la detección de anomalías
Puede detectar anomalías y valores atípicos en los datos con la ayuda de diferentes algoritmos de minería de datos para la clasificación, el agrupamiento o el aprendizaje de reglas de asociación.
Por lo general, estos algoritmos de minería de datos se clasifican en dos categorías diferentes : algoritmos de aprendizaje supervisados y no supervisados.
Aprendizaje supervisado
El aprendizaje supervisado es un tipo común de algoritmo de aprendizaje que consta de algoritmos como máquinas de vectores de soporte, regresión logística y lineal, y clasificación multiclase. Este tipo de algoritmo se entrena con datos etiquetados, lo que significa que su conjunto de datos de entrenamiento incluye tanto datos de entrada normales como la salida correcta correspondiente o ejemplos anómalos para construir un modelo predictivo.
Por lo tanto, su objetivo es hacer predicciones de salida para datos nuevos e invisibles en función de los patrones del conjunto de datos de entrenamiento. Las aplicaciones de los algoritmos de aprendizaje supervisado incluyen reconocimiento de imagen y voz, modelado predictivo y procesamiento de lenguaje natural (NLP).
Aprendizaje sin supervisión
Aprendizaje sin supervisión no está capacitado en ningún dato etiquetado. En cambio, descubre procesos complicados y estructuras de datos subyacentes sin proporcionar la guía del algoritmo de entrenamiento y en lugar de hacer predicciones específicas.
Las aplicaciones de los algoritmos de aprendizaje no supervisados incluyen detección de anomalías, estimación de densidad y compresión de datos.
Ahora, exploremos algunos algoritmos populares de detección de anomalías basados en aprendizaje automático.
Factor de valores atípicos locales (LOF)
Local Outlier Factor o LOF es un algoritmo de detección de anomalías que considera la densidad de datos locales para determinar si un punto de datos es una anomalía.
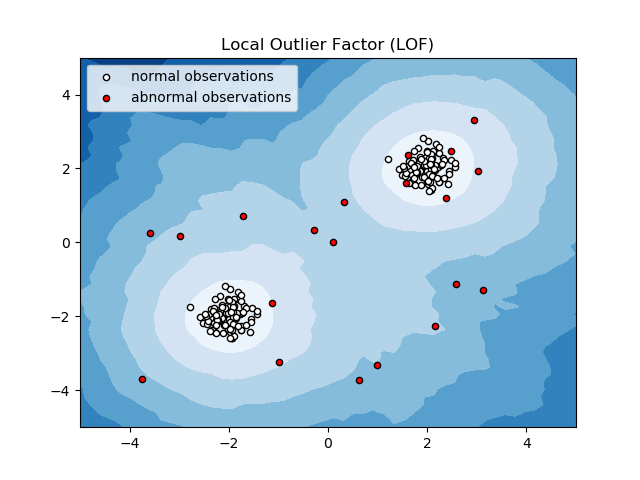
Compara la densidad local de un elemento con las densidades locales de sus vecinos para analizar áreas de densidades similares y elementos con densidades comparativamente más bajas que sus vecinos, que no son más que anomalías o valores atípicos.
Por lo tanto, en términos simples, la densidad que rodea a un elemento atípico o anómalo difiere de la densidad que rodea a sus vecinos. Por lo tanto, este algoritmo también se denomina algoritmo de detección de valores atípicos basado en la densidad.
K-Vecino más cercano (K-NN)
K-NN es el algoritmo de detección de anomalías supervisado y clasificación más simple que es fácil de implementar, almacena todos los ejemplos y datos disponibles, y clasifica los nuevos ejemplos en función de las similitudes en las métricas de distancia.
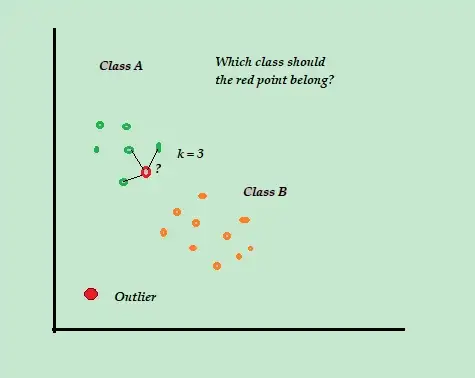
Este algoritmo de clasificación también se denomina aprendiz perezoso porque solo almacena los datos de entrenamiento etiquetados, sin hacer nada más durante el proceso de entrenamiento.
Cuando llega el nuevo punto de datos de entrenamiento sin etiquetar, el algoritmo busca los K-puntos de datos de entrenamiento más cercanos o más cercanos para usarlos para clasificar y determinar la clase del nuevo punto de datos sin etiquetar.
El algoritmo K-NN utiliza los siguientes métodos de detección para determinar los puntos de datos más cercanos:
- Distancia euclidiana para medir la distancia de datos continuos.
- Distancia de Hamming para medir la proximidad o "cercanía" de las dos cadenas de texto para datos discretos.
Por ejemplo, considere que sus conjuntos de datos de entrenamiento constan de dos etiquetas de clase, A y B. Si llega un nuevo punto de datos, el algoritmo calculará la distancia entre el nuevo punto de datos y cada uno de los puntos de datos en el conjunto de datos y seleccionará los puntos que son el número máximo más cercano al nuevo punto de datos.
Entonces, suponga que K=3, y 2 de los 3 puntos de datos están etiquetados como A, luego el nuevo punto de datos está etiquetado como clase A.
Por lo tanto, el algoritmo K-NN funciona mejor en entornos dinámicos con requisitos de actualización de datos frecuentes.
Es un algoritmo popular de detección de anomalías y minería de texto con aplicaciones en finanzas y negocios para detectar transacciones fraudulentas y aumentar la tasa de detección de fraude.
Máquina de vectores de soporte (SVM)
La máquina de vectores de soporte es un algoritmo de detección de anomalías basado en el aprendizaje automático supervisado que se utiliza principalmente en problemas de regresión y clasificación.
Utiliza un hiperplano multidimensional para segregar los datos en dos grupos (nuevos y normales). Por lo tanto, el hiperplano actúa como un límite de decisión que separa las observaciones de datos normales y los nuevos datos.
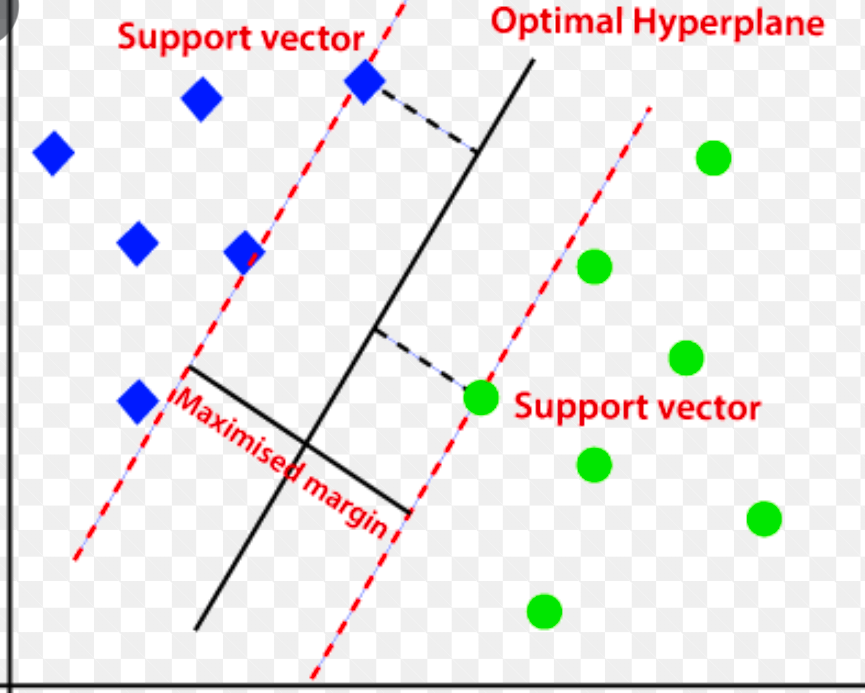
La distancia entre estos dos puntos de datos se denomina márgenes.
Dado que el objetivo es aumentar la distancia entre los dos puntos, SVM determina el hiperplano mejor u óptimo con el margen máximo para garantizar que la distancia entre las dos clases sea lo más amplia posible.
Con respecto a la detección de anomalías, SVM calcula el margen de la observación del nuevo punto de datos del hiperplano para clasificarlo.
Si el margen supera el umbral establecido, clasifica la nueva observación como una anomalía. Al mismo tiempo, si el margen es menor que el umbral, la observación se clasifica como normal.
Por lo tanto, los algoritmos SVM son altamente eficientes en el manejo de conjuntos de datos complejos y de alta dimensión.
Bosque de aislamiento
Isolation Forest es un algoritmo de detección de anomalías de aprendizaje automático no supervisado basado en el concepto de un clasificador de bosque aleatorio.
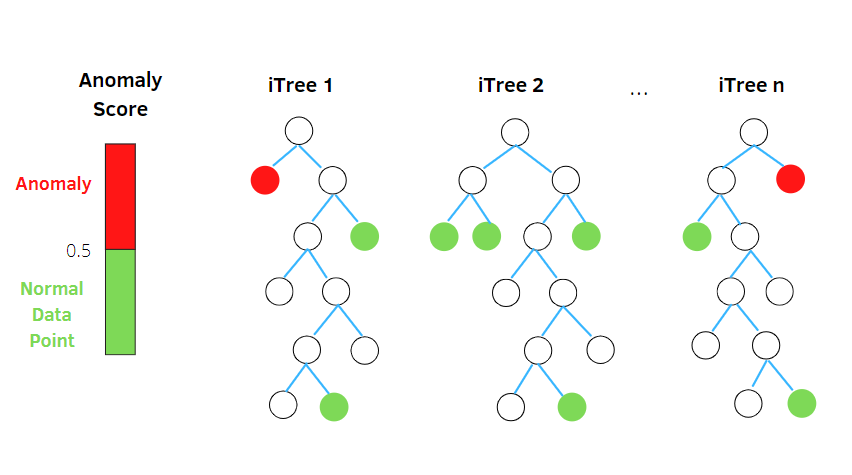
Este algoritmo procesa datos submuestreados aleatoriamente en el conjunto de datos en una estructura de árbol basada en atributos aleatorios. Construye varios árboles de decisión para aislar las observaciones. Y considera una observación en particular una anomalía si está aislada en menos árboles en función de su tasa de contaminación.
Por lo tanto, en términos simples, el algoritmo del bosque de aislamiento divide los puntos de datos en diferentes árboles de decisión, lo que garantiza que cada observación se aísle de las demás.
Las anomalías generalmente se encuentran lejos del grupo de puntos de datos, lo que facilita la identificación de las anomalías en comparación con los puntos de datos normales.
Los algoritmos de bosque de aislamiento pueden manejar fácilmente datos categóricos y numéricos. Como resultado, son más rápidos de entrenar y altamente eficientes en la detección de anomalías de conjuntos de datos grandes y de alta dimensión.
Rango intercuartil
El rango intercuartílico o IQR se usa para medir la variabilidad estadística o la dispersión estadística para encontrar puntos anómalos en los conjuntos de datos dividiéndolos en cuartiles.
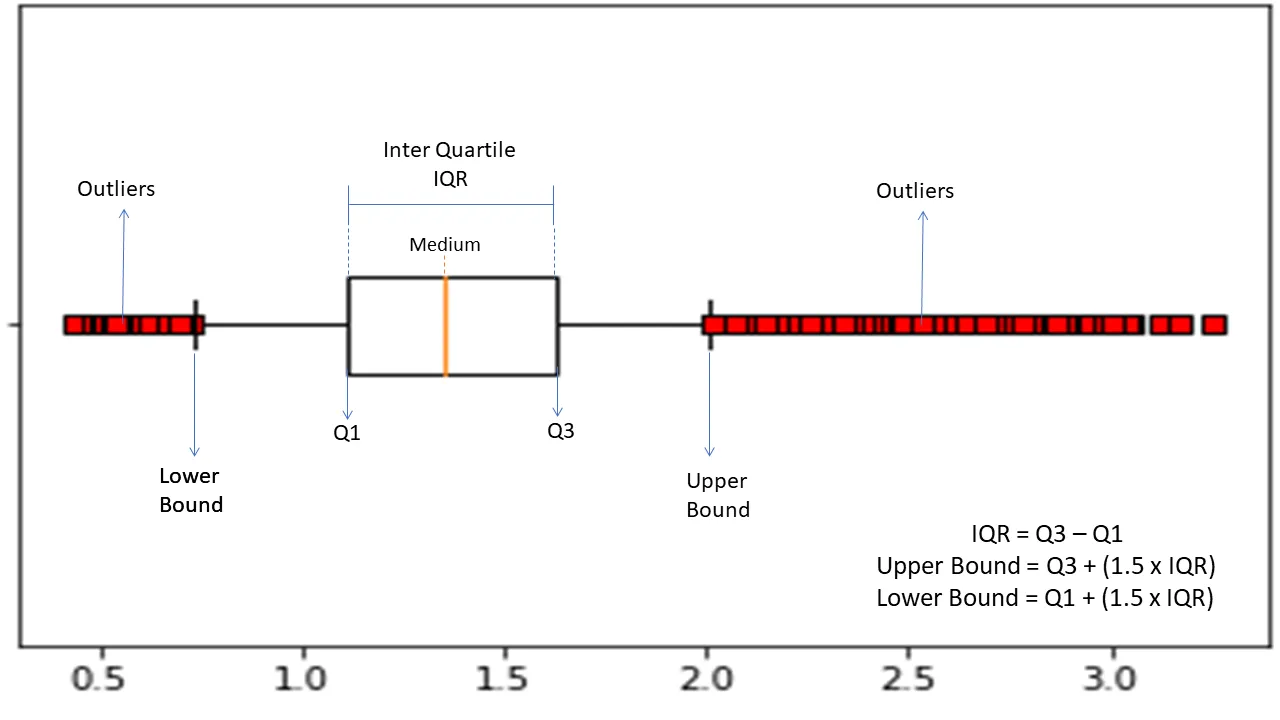
El algoritmo ordena los datos en orden ascendente y divide el conjunto en cuatro partes iguales. Los valores que separan estas partes son los cuartiles Q1, Q2 y Q3: primero, segundo y tercero.
Aquí está la distribución percentil de estos cuartiles:
- Q1 significa el percentil 25 de los datos.
- Q2 significa el percentil 50 de los datos.
- Q3 significa el percentil 75 de los datos.
IQR es la diferencia entre los conjuntos de datos del percentil tercero (75) y primero (25), que representan el 50% de los datos.
El uso de IQR para la detección de anomalías requiere que calcule el IQR de su conjunto de datos y defina los límites inferior y superior de los datos para encontrar anomalías.
- Límite inferior: Q1 – 1.5 * IQR
- Límite superior: Q3 + 1,5 * IQR
Por lo general, las observaciones que caen fuera de estos límites se consideran anomalías.
El algoritmo IQR es efectivo para conjuntos de datos con datos distribuidos de manera desigual y donde la distribución no se comprende bien.
Ultimas palabras
Los riesgos de seguridad cibernética y las filtraciones de datos no parecen disminuir en los próximos años, y se espera que esta industria riesgosa crezca aún más en 2023, y se prevé que los ataques cibernéticos de IoT solo se dupliquen para 2025.
Además, los delitos cibernéticos costarán a las empresas y organizaciones globales un estimado de 10,3 billones de dólares anuales para 2025.
Esta es la razón por la que la necesidad de técnicas de detección de anomalías es cada vez más frecuente y necesaria hoy en día para la detección de fraudes y la prevención de intrusiones en la red.
Este artículo lo ayudará a comprender qué son las anomalías en la minería de datos, los diferentes tipos de anomalías y las formas de prevenir las intrusiones en la red mediante técnicas de detección de anomalías basadas en ML.
A continuación, puede explorar todo sobre la matriz de confusión en el aprendizaje automático.